





مقدمه:
کامپیوترهای کوانتومی، ماشینهایی هستند که مبتنی بر بیتهای کوانتومی هستند که از قوانین مکانیک کوانتومی بهره کامل میبرند. آنها وعده عملکرد بهتر از قابلیتهای محاسباتی کلاسیک فعلی را دارند. این انتظار وجود دارد که یادگیری ماشین یکی از تاثیر گذارترین برنامههای قاتل برای نسل اول کامپیوترهای کوانتومی تجاری در دسترس باشد و به ویژه برای سخت افزاری که در طول به اصطلاح کوانتومی با مقیاس متوسط پر سروصدا (NISO) بر چشمانداز عصر کامپیوترهای کوانتومی تسلط داشته باشد. پیشبینی میشود که یادگیری ماشین در کوتاه مدت هم توسط آنیل کنندههای کوانتومی آدیاباتیک (A0A) و هم از کامپیوترهای کوانتومی دروازهدار تاثیر میپذیرد. A0Aهای تجاری با بیش از ۱۰۰ کیوبیت برای بیش از یک دهه در دسترس بودهاند، درحالیکه در حال حاضر هیچ کامپیوترهای کوانتومی دروازهای با بیش از ۱۰۰ کیوبیت به صورت تجاری در دسترس نیست. در نتیجه، در حال حاضر سابقهای غنی از به کارگیری AOA در مشکلات یادگیری ماشین وجود دارد. از سوی دیگر، سخت افزار کامپیوترهای کوانتومی دروازهای امروزه توجه زیادی را به خود جلب میکند، زیرا این پایهای است که یک کامپیوتر کوانتومی باهدف عمومی (و نه یک برنامه خاص) آینده بر آن استوار است. پیشرفتهای اخیر در سخت افزار کامپیوتر کوانتومی، الگوریتمها، و برنامههای کاربردی اثبات مفهوم اولیه نشان میدهد که این دستگاهها نیز نفوذ قابل توجهی به یادگیری ماشین داشتهاند و آنها در حال حاضر از سهم بزرگی از انتشارات علمی مرتبط با کوانتومی یادگیری ماشین برخوردار هستند. یکی دیگر از رویکردهایی که در سالهای اخیر به آن پرداخته شده است مربوط به محاسبات کوانتومی از جمله محاسبات مبتنی بر بر بازپخت و گیت محوره است. پیادهسازی این رویکردها برای یافتن خط مشی بهینه برای عبور از یک شبکه و مقایسه آنها با رویکرد یادگیری تقویت عمیق کلاسیک ارائه میدهد.
روش تحقیق
در این تحقیق حدود ۲۱۰ مقاله که با کلید واژههای ارائه شده مرتبط بود از طریق پایگاههای علمی معتبر مورد بررسی قرار گرفت که با بررسی چکیدهها و در برخی از موارد متن مقاله بسیاری از آنها از چرخه مطالعه خارج و در نهایت ۵ مقاله به عنوان مقاله پایه و از سایر مقالات نیز بخشهایی در بعضی از تعاریف مورد استفاده قرار گرفت.
اصول یادگیری ماشینی
یادگیری ماشینی یک علم چندرشتهای است که الگوریتمهای مختلف را برای استخراج اطلاعات معنیدار از دادههای موجود و ارائه راه حلهای خودکار برای مسائل پیچیده محاسباتی مطالعه میکند. قدرت الگوریتمهای یادگیری ماشین در توانایی آنها برای یادگیری از دادههای موجود نهفته است و به این ترتیب یادگیری ماشین به جای مدلسازی، مبتنی بر داده است و دارای سه مدل یادگیری نظارت شده، یادگیری بدون نظار و یادگیری تقویتی است.
معرفی مدل یادگیری تقویتی
همانطور که در بخش قبل بیان شد یکی از مدلهای یادگیری ماشین، مدل یادگیری تقویتی است. یادگیری تقویتی را میتوان برای تا تعیین تعاملات اجتماعی و اقتصادی بهینه کاربردهای مختلف، از روباتهای مستقل استفاده کرد. یادگیری تقویتی عوامل هوشمندی را طراحی میکند که قادر به تعامل با دنیای بیرون برای انجام موفقیتآمیز وظایف خاص، مانند یافتن یک هدف یا به دست آوردن پاداشهای خاص هستند. در طول سالها، یادگیری تقویتی پیشرفتهای زیادی را به خود دیده است، به ویژه استفاده از شبکههای عصبی برای رمزگذاری کیفیت ترکیبهای حالت - عمل. از آن زمان به بعد، با موفقیت در بازیهای پیچیدهای مانند Go و حل مکعب روبیک اعمال شد.
مدلهای یادگیری تقویتی برای کاوش در یک محیط ناشناخته به صورت مقرون به صرفه مفید هستند. در محیطهای متخاصم، انتخاب بهترین راه ممکن میتواند مرگ و زندگی باشد، بنابراین، مدلهای یادگیری ماشین مصنوعی اغلب به بهترین تصمیم کمک میکنند. مدلهای یادگیری تقویتی میتوانند یک مسیر مقرون به صرفه را از طریق محیطهای ناشناخته پیدا کنند. با ارائه مدل یادگیری تقویتی با یک نمای کلی ساده از محیط، همراه باهدف و مکانها یا مسیرهای احتمالاً خطرناکی که طرفهای دشمن کنترل میکنند، مدل مسیری را جستجو میکند که به هدف برسد و در عین حال کمترین هزینه را متحمل شود. تعریف هزینه در هر مورد استفاده متفاوت است. اگر بخواهیم مسیری بین دو نقطه پیدا کنیم، میتوانیم هزینه را به عنوان طول مسیر یافت شده تعریف کنیم، اما در شرایط خصمانه، باید هزینه را به عنوان معیاری برای ایمنی یک مسیر خاص تعریف کنیم. مدل یادگیری تقویتی به طور موثر سیاستی را میآموزد که دیکته میکند کدام عمل باید در یک وضعیت انجام شود. پاداش تجمعی آینده مورد انتظار یک ترکیب حالت - عمل معین، ارائه شده توسط (s, a)Q کیفیت یک سیاست معین را تعیین میکند.
در محیطهای ساده، حتی بدون محاسبه صریح مقادیر Q میتوان خط مشی بهینه را به راحتی پیدا کرد. با اینحال، در محیطهای پیچیده با متغیرهای زیاد، انسانها در یافتن مسیر بهینه با مشکل مواجه میشوند و مدلهای کامپیوتری کار را به دست میگیرند. با پیچیدهتر شدن محیطها، حتی رایانهها نیز میتوانند مشکلاتی داشته باشند و قدرت محاسباتی آنها گاهی اوقات کافی نیست. این باعث پیشرفت یادگیری میشود، مانند یادگیری برنامه درسی که در آن به تدریچ محیط را پیچیده میکند. پیشرفتهای محاسباتی مبتنی بر سخت افزار، مانند یادگیری تقویتی توزیع شده در سیستمهای CPU-GPU و یادگیری تقویتی کوانتومی میباشند.
در سالهای اخیر در این حوزهها تحقیقات زیادی انجام شده است، هم با استفاده از رایانههای کوانتومی مبتنی بر گیت و هم از رایانههای کوانتومی مبتنی بر بازپخت به عنوان پلت فرم محاسباتی. رویکردهای مبتنی بر گیت میتوانند از الگوریتم جستجوی گراور برای یافتن بهترین اقدام جدید یا مدلسازی تعاملات پیچیده بین عامل و محیط در برهم نهی استفاده کنند. در اینجا، مرحله یادگیری تا حدی کوانتومی است و خط مشی بهینه با استفاده از منابع کلاسیک یا کوانتومی ذخیره میشود. رویکرد کوانتومی مبتنی بر بازپخت شامل یک الگوريتم براى آموزش كارآمد ماشين بولتزمن كوانتومى با استفاده از يك آنيل كوانتومى است، ماشين كوانتومى بولتزمن خط مشى بهينه را ذخيره مىكند.
سخت افزار كوانتومى فعلى هنوز در دست توسعه است و سخت افزار معمولا نويز دارد بنابراين، دستگاههاى كوانتومى فعلى، دستگاههاى كوانتومى در مقياس متوسط نويز ناميده میشوند. با اين حال، حتى اين دستگاههاى NISO قبلاً در حل مسائل خاص مفيد هستند. دستگاههاى NISO مبتنى بر گيت مىتوانند به شبيهسازى سيستمهاى چند بدنه كوانتومى كمك كنند. علاوه بر اين، هر دو دستگاه NISO مبتنى بر گيت و مبتنى بر بازپخت مىتوانند به حل مشكلات بهينهسازى كمک كنند، به عنوان مثال مىتوان به تهديد رمزگذارى AES با فرمول بندى آن به عنوان يک مسئله بهينهسازى و پيادهسازى مدلهاى يادگيرى ماشين كوانتومى و شبكههاى عصبى كوانتومى اشاره کرد.
در ادامه قابليتهاى يادگيرى ماشين كوانتومى را براى يادگيرى تقويتى تحليل میشود. عملكرد هر دو روش كوانتومى مبتنى بر گيت و مبتنى بر بازپخت را با رويكرد مبتنى بر يادگيرى تقويت عميق كلاسيك مقايسه میشود. به طور خاص عواملى را در يك محيط ناشناخته در نظر مىگيريم كه بايد به يك هدف برسند. محيط ناشناخته مىتواند هم حالتهاى مانع و هم حالتهاى مجازات داشته باشد. بازديد از ايالت جريمه هزينه زيادى را به همراه خواهد داشت. همچنين امكان تصادفى بودن را در اقدامات عاملها فراهم مىكند، با توجه به يك حالت و يك عمل، عاملها فقط با احتمال كمى به حالت مورد نظر حركت مىكنند و در غير اين صورت به موقعيت شبكه مجاور حركت مىكنند. همچنين يك تكنيك يادگيرى بهبود يافته به نام يادگيرى برنامه درسى را معرفى شده است كه در آن محيط به تدريج پيچيدهتر میشود. در مقالهای، يك رويكرد براى پيمايش شبكه براى عوامل منفرد با استفاده از آنيل كوانتومى ارائه شده است. اين كار بعداً به تنظيمات با چندين عامل كه به طور جمعى به اهداف خاصى میرسند در گسترش يافت.
در بخشهاى بعدى ابتدا كارهاى انجام شده در اين حوزه، سپس دو رويكرد كوانتومى براى پيادهسازى مدلهاى يادگيرى تقويتى را مورد بررسى قرار میدهيم. سپس، مجموعه آزمايشى كه در مقالات اين حوزه انجام شده است را توضيح خواهيم داد و نتايج را با يادگيرى تقويتى كلاسيك مقايسه و بحث خواهيم كرد.
رويكرد محاسبات كوانتومى
كامپيوترهاى كوانتومى از اثرات كوانتومى براى انجام محاسبات استفاده مىكنند. روشى كه رايانههاى كوانتومى اين عمليات را اجرا مىكنند و اينكه كدام عمليات پشتيبانى میشوند، مىتواند متفاوت باشد. دو رويكرد رايج براى محاسبات كوانتومى، محاسبات كوانتومى مبتنى بر بازپخت و محاسبات كوانتومى مبتنى بر گيت است. اين رويكردها به ترتيب مشابه محاسبات آنالوگ كلاسيك و محاسبات ديجيتال كلاسيك هستند.
رويكرد محاسبات كوانتومى مبتنى بر آنيل
محاسبات كوانتومى مبتنى بر بازپخت يا آنيل كوانتومى بر اساس كار كادواكى و نيشى مور است. بسيارى از مسائل قبلاً با استفاده از آنيل كوانتومى، ارائه راه حلهاى معقول در زمان واقعى يا ارائه راه حلهاى بهينه يا بسيار خوب سريعتر از جايگزينهاى كلاسيك حل شدهاند. كاربردهاى آنيل كوانتومى متنوع است و شامل بهينهسازى ترافيك، امور مالى، مشكلات امنيت سايبرى و يادگيرى ماشينى است. در بازپخت كوانتومى، كيوبيتها در حالت برهمنهى اوليه قرار مىگيرند و بس از آن يك هميلتونى مخصوص مسئله بر روى كيوبيتها اعمال میشود. اگر هميلتون به اندازه كافى آهسته اعمال شود، كيوبيتها در حالت پايه مورد نظر باقى میمانند و اندازهگيرى پاسخ مسئله در نظر گرفته شده را نشان میدهد. رويكرد كوانتومى مبتنى بر بازپخت پيشنهادى به صراحت تابع Q را براى تعيين خط مشى بهينه محاسبه مىكند. اين تابع Q را مىتوان توسط يك ماشين بولتزمن رمزگذارى كرد كه داراى يك شبكه عصبى كه در آن همه گرهها مىتوانند متصل شوند است. ماشينهاى محدود بولتزمن نوع خاصى از ماشينهاى بولتزمن هستند كه در آنها گرهها به گرههاى قابل مشاهده v و گرههاى نهان h تقسيم میشوند و اتصالات فقط بين گرههاى گروههاى مختلف وجود دارد. گرههاى قابل مشاهده به حالتها و اقدامات ممكن مربوط میشوند، میتوانيم گرههاى پنهان را در چندين لايه پنهان تقسيم نموده كه در آن صورت، اتصالات فقط بين گرههاى لايههاى بعدى وجود دارد. يالها گرههاى مختلف را به هم متصل مىكنند و وزنهايى را مىتوان به اين يالها اختصاص داد، وزن مثبت (منفى) نشاندهنده ترجيح دو گره مرتبط براى رسيدن به يك مقدار (مخالف) است. گرهها يكى از دو مقدار ممكن ا± را مىگيرند. با استفاده از وزنهاى اختصاص داده شده به گرهها، مىتوانيم اولويت را براى يكى از دو مقدار نشان دهيم. ماشينهاى محدود بولتزمن مدلهاى lsing تصادفى هستند بنابراين، آنيل كنندههاى كوانتومى مىتوانند به تعيين انرژى مرتبط با يك ماشين محدود بولتزمن كمك كنند. انرژى يك ماشين بولتزمن محدود شده توسط جايى كه vi و hj ذرات ariable هستند كه مقادير گرههاى مرئى و پنهان را نشان میدهند و wij وزن بين گرههاى i و j را نشان میدهد. طبق تعريف، اگر گرههای i و j در لايههاى بعدى نباشند، wij=0 است. همه اوزان دوطرفه هستند.
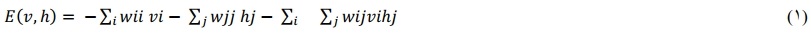
براى آموزش يك ماشين محدود شده بولتزمن، ابتدا گرههاى قابل مشاهده را تعمير مىكنيم كه به طور مؤثر تركيب حالت -عمل را برطرف مىكند. سيس، از آنيل كوانتومى براى تعيين مؤثر انرژى اين جفت استفاده میشود و در نهايت، وزن ماشين محدود شده بولتزمن را براى بهبود عملكرد، بر اساس برخى معيارها، بهروز خواهد شد. متريك استفاده شده مىتواند بين موارد استفاده متفاوت باشد. جزئيات بيشتر در مورد پيادهسازى در آورده شده است. مىتوان كارايى ماشين محدود شده بولتزمن را با اعمال انباشته كردن ماكت افزايش داد: چندين نسخه از طرحبندى يكسان به طور همزمان به سخت افزار نگاشت میشوند و متغيرهاى مربوطه در كپیهاى مختلف جفت میشوند. اين احتمال يافتن پيكربندیهاى غيربهينه را كاهش میدهد، بايد توجه داشت كه سخت افزار موجود، اندازه محيط رمزگذارى شده و تعداد اقدامات طبيعتاً محدوديتى بر تعداد نسخههایی که میتوان استفاده کرد، اعمال میکند. ماشین محدود بولتزمن و وزنهای آن خط مشی موقت را رمزگذاری میکند. با تنظیم وزنهها میتوانیم خطمشی بهتری یاد بگیریم.
رویکرد کوانتومی مبتنی بر دروازه
محاسبات کوانتومی مبتنی بر گیت از بسیاری جهات شبیه کامپیوترهای دیجیتال معمولی است. بیشتر مفاهیم کلاسیک با معادل کوانتومی مستقیم خود جایگزین میشوند: بیتهای کوانتومی (کیوبیت) جایگزین بیتها و عملیات کیوبیت جایگزین عملیات بیت میشوند. یک تفاوت کلیدی این است که عملیات کوانتومی باید برگشتپذیر باشد. با این حال، تمام عملیات کلاسیک را میتوان با افزودن بیتهای اضافی برگشتپذیر کرد. کامپیوترهای کوانتومی مبتنی بر گیت عملیات را با دستکاری دقیق کیوبیتهای خاص به ترتیب خاصی انجام میدهند. حالت کوانتومی حاصل پاسخ را نگه میدارد و اندازهگیری تنها یکی از نتایچ ممکن را با احتمال متناسب با مجذور دامنه آن نتیجه خاص نشان میدهد. برای رویکرد کوانتومی مبتنی بر دروازه، به جای مدلسازی بر همکنشهای پیچیده عامل-محیط به روش کوانتومی، همانطور که رویکرد گراور چنین است، رویکردی را انتخاب کردیم که از الگوریتم جستجوی گراور برای یافتن بهترین اقدام استفاده میکند. برای دستگاههای NISO مناسبتر است. در عوض، پیادهسازی که تعاملات پیچیده عامل-محیط را در برهمنهی مدلسازی میکند، نیاز به سربار قابل توجهی برای تصحیح خطا دارد.
رویکرد کوانتومی مبتنی بر گیت، یک خط مشی موقت را در طول یادگیری ذخیره میکند که بهترین عملکرد را برای هر حالت، همراه با پاداش مورد انتظار از آن حالت حفظ میکند. این رویکرد پس از پایان آموزش، خط مشی ذخیره شده را بر میگرداند. در هر تکرار، با استفاده از الگوریتم جستجوی گراور، بهترین اقدام را از یک حالت شروع میشود. اجازه داده میشود تعداد تکرارهای استفاده شده Grover به پاداش مورد انتظار ترکیب موقت حالت -اقدام سیاست بستگی داشته باشد. به این ترتیب، اطمینان پیدا میشود که پس از یافتن آنها و گنجاندن آنها در خط مشی موقت، اغلب اقدامات خوب را پیدا میکند.
آزمایشها و نتایچ بررسی شده
تنظیم آزمایشی
برای پیادهسازی مدل یادگیری تقویتی، دو رویکرد کوانتومی وجود دارد، یک رویکرد کوانتومی مبتنی بر بازپخت که یک ماشین بولتزمن محدود را پیادهسازی میکند و یک رویکرد کوانتومی مبتنی بر دروازه که از الگوریتم جستجوی گراور برای یافتن عمل بهینه استفاده میکند. ما هر دو مدل کوانتومی را با یک مدل مقایسه میکنیم. رویکرد یادگیری تقویتی عمیق کلاسیک ما عملکرد این رویکردها را در چندین محیط مختلف ارزیابی میکنیم. در طول مرحله آموزش هر یک از رویکردها، بهترین خط مشی ارائه شده توسط ترکیب دولت -عمل آموخته میشود.
محیطهای مورد استفاده
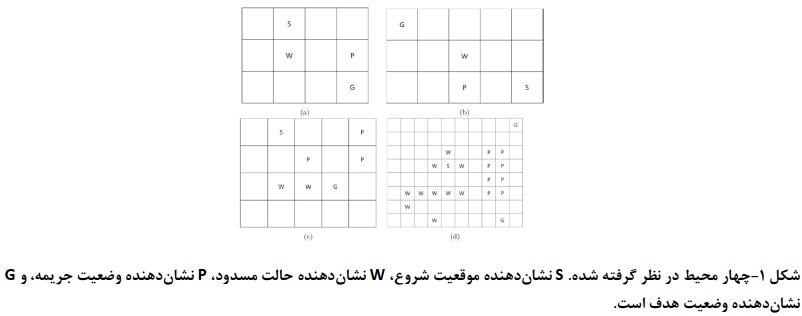
شکل 1 محیطهای مورد استفاده را نشان میدهد. محیطها شامل یک یا چند حالت شروع S و یک یا چند حالت هدف G هستند. یک عامل در حالت شروع، شروع میشود و از یک خط مشی آموخته شده برای رسیدن به هدف پیروی میکند. این خط مشی با استفاده از یکی از سه رویکرد در نظر گرفته شده آموخته میشود. علاوه بر این، محیطها شامل حالتهای مسدود شده W و حالتهای مجازات P هستند. از هر حالت، عوامل میتوانند چهار عمل انجام دهند: حرکت به بالا، پایین، چپ و راست. اگر یک عمل باعث شود یک عامل به خارج از محیط حرکت کند یا به حالت مسدود شود، مرحله زمانی بدون تغییر موقعیت عامل پیش میرود. عواملی که از یک حالت پنالتی بازدید میکنند، دارای پاداش منفی منهای دویست هستند، در حالیکه رسیدن به حالت هدف، پاداش مثبت دویست را میدهد. بزرگی هر دو مقدار را برابر میگیریم، زیرا باید از حالت پنالتی به همان اندازه که باید به هدف رسید نمایندگان اگر قدمی بردارند پاداش منفی کوچکی منهای ده دریافت میکنند. به صراحت این مقدار را به طور قابل توجهی کوچکتر از پاداش در حالت هدف انتخاب میشود. این هزینه اندک برای برداشتن یک گام، مسیرهای مستقیم را بر مسیرهای انحرافی ترجیح میدهد.
کنشهای تصادفی
به عوامل اجازه داده میشود که اقدامات قطعی یا تصادفی انجام دهند. با اقدامات تصادفی، یک عامل عملی را با احتمال تنظیمپذیر p انجام میدهد و با احتمال ![]() یکی از دو عمل مجاور به جای آن انجام میشود. به عنوان مثال، برای p = 0.9، یک عامل با احتمال ۰.۹ به سمت بالا حرکت میکند و هر کدام با احتمال ۰۵ .0 به سمت راست یا چب حرکت میکند. اگر p=1 باشد، عمل را قطعی میدانیم، در غیر این صورت، آنها را تصادفی مینامیم.
یکی از دو عمل مجاور به جای آن انجام میشود. به عنوان مثال، برای p = 0.9، یک عامل با احتمال ۰.۹ به سمت بالا حرکت میکند و هر کدام با احتمال ۰۵ .0 به سمت راست یا چب حرکت میکند. اگر p=1 باشد، عمل را قطعی میدانیم، در غیر این صورت، آنها را تصادفی مینامیم.
اندازهگیری عملکرد
میتوان عملکرد یک خط مشی آموخته شده را با استفاده از پاداش مورد انتظار کمی نمود. آثار قبلی نیز وفاداری یک سیاست را در نظر میگرفتند. وفاداری برابر با کسری از حالاتی است که عمل صحیحی به آن اختصاص داده شده است. تعیین اقدام صحیح در هر حالت معمولا مستلزم ارزیابی صریح محیط است. این فقط برای محیطهای کوچک و نسبتاً ساده قابل اجرا است و بنابراین فقط از وفاداری برای توسعه و آزمایش عملکرد یک رویکرد استفاده میشود، نه برای ارزیابی نهایی. برای محاسبه پاداش مورد انتظار، اقدامات ارائه شده توسط خط مشی را دنبال میشود، از یک حالت شروع از پیش تعریف شده شروع شده و مجموع پاداشها را در هر مرحله پیگیری میشود. ارزیابی این معیار مستقل از اندازه محیط ساده است بنابراین فقط پاداش مورد انتظار را در ارزیابی عملکرد یک سیاست در نظر میگیریم.
مرحله آموزش و راهبردهای یادگیری
در مقالههای پایه برای تعداد ثابتی از تکرارهای آموزشی تمرین و پاداش مورد انتظار را در طول آموزش محاسبه شده است. در هر دو رویکرد کوانتومی، هر تکرار آموزشی از یک ترکیب حالت - عمل واحد تشکیل شده است. برای رویکرد یادگیری تقویت عمیق کلاسیک، یک تکرار آموزشی یک ارزیابی از یک مسیر از نقطه شروع تا هدف است. برای این تفاوت انتخاب میکنیم; زیرا در غیر این صورت تعداد تکرارهای آموزشی برای رویکرد تقویت عمیق کلاسیک بسیار زیاد خواهد بود. محاسبه پاداش مورد انتظار، از یک موقعیت شروع S شروع و این خط مشی را تا رسیدن به یک حالت هدف یا بازدید حداکثری از وضعیتها دنبال میشود. این حداکثر تعداد حالتها بهعنوان تعداد حالتهای متمایز در محیط در نظر گرفته میشود. در صورت اعمال تصادفی، این عمل را سی بار تکرار و از نتایچ میانگین میگیریم. در مجموع، به طور مستقل سه رویکرد را ده بار آموزش و میانگین نتایچ یافت شده را در این ده اجرا میشود. این تغییرات احتمالی را در طول مرحله تمرین جبران میکند.
همچنین از دو استراتژی آموزشی متفاوت استفاده میشود. در استراتژی آموزشی اول، هر یک از سه رویکرد را با کل محیط ارائه میکنیم، در حالیکه در استراتژی دوم به تدریچ پیچیدگی محیط را در طول آموزش افزایش میدهیم. استراتژی اول را یادگیری مستقیم و استراتژی دوم را یادگیری برنامه درسی نامیده میشود. در یادگیری برنامه درسی، محیط در ابتدا فقط شامل حالات انسدادی است. پس از تعداد ثابتی از تکرارهای آموزشی، محیط را با اضافه کردن حالتهای پنالتی و بعداً اقدامات تصادفی پیچیده میکنیم. همچنین اقدامات تصادفی را به تدریچ معرفی خواهیم نمود، ابتدا با مقادیر p بالا یاد میگیریم و به تدریچ p را کاهش میدهیم، جایی که p احتمال انجام عمل صحیح آن است.
انتخاب فراپارامتر
سه رویکرد در نظر گرفته شده دارای برخی فراپارامترهایی هستند که باید تنظیم شود، برای هر دو رویکرد کوانتومی، همچنین باید تعداد نمونههای کوانتومی را که در هر تکرار آموزشی گرفته شود، تعیین نماییم. دو ابر پارامتر آخر نرخ یادگیری و ضریب تخفیف هستند. این ضریب تخفیف ارزش فعلی پاداشهای آینده را میسنجد: پاداش آتی کمتر از همان پاداشی است که اکنون به دست میآید. مقادیر کاندید را برای هر یک از فراپارامترها بر اساس انتخاب و یک جستجوی شبکهای بروی ترکیبات ممکن برای یافتن بهترین تنظیمات انجام میشود. کیفیت هر تنظیم را با محاسبه وفاداری خط مشی آموخته شده تعیین میشود. از محیط ۳x۵ - نشان داده شده در شکل b۱ برای یافتن فراپارامترها استفاده شده است، زیرا میتوان خطمشی بهینه را برای این محیط با یک بازرسی سریع بصری پیدا نمود. تنظیما فراپارامتر را انتخاب شده است که بالاترین میانگین وفاداری را در پنچ اجرا مستقل ارائه میکند. اگر دو تنظیمات عملکرد متوسط مشابهی را نشان دادند، تنظیمات با پایدارترین عملکرد و سریعترین همگرایی را انتخاب میشود.
راه اندازی شبیه سازی
نتایچ هر دو رویکرد کوانتومی را با رویکرد یادگیری تقویتی عمیق کلاسیک مقایسه شده است. در این رویکرد کلاسیک، یک عامل از حالت شروع، شروع به کاوش در محیط میکند و امیدوار است که یک حالت هدف پیدا کند. با توجه به زمان تمرین کافی، استراتژی عامل بهبود مییابد و او سریعتر حالت هدف را پیدا میکند. نحوه آموزش با دو رویکرد کوانتومی متفاوت است، به ویژه در این که هیچ خط مشی صریحی رعایت نمیشود و در یک تکرار آموزشی از رویکرد یادگیری تقویتی عمیق کلاسیک، ما مدل را برای یک مسیر کامل به جای یک حالت واحد به روز میشود. رویکرد یادگیری تقویت عمیق کلاسیک را به صورت محلی روی یک کامپیوتر شخصی ساده آموزش داده و هر دو رویکرد کوانتومی را شبیهسازی شده است: رویکرد مبتنی بر بازپخت کوانتومی با استفاده از مدلهای بازپخت شبیهسازی شده توسط بسته نرمافزار Ocean توسط D-Wave و رویکرد کوانتومی مبتنی بر دروازه با استفاده از بسته نرمافزاری کوانتومی aiskit اجرا گردید. انتظار میرود که هر دو رویکرد کوانتومی عملکرد مشابهی را روی سختافزار کوانتومی واقعی نشان دهند، حتی در دستگاههای NISQ هنوز در معرض نویز هستند.
نتایچ یادگیری برنامه درسی در مقابل یادگیری مستقیم
در این بخش، با استفاده از برخی از محیطهای شکل 1، عملکرد یادگیری برنامه درسی را با یادگیری مستقیم مقایسه میشود. برای هر محیط، پس از نیمی از مراحل آموزشی، حالتهای جریمه را اضافه و در نتیجه محیط را پیچیده میکند. از پاداش مورد انتظار برای تعیین کمیت عملکرد یک سیاست استفاده شده است. در اولین آزمونها، تصادفی بودن بروی صفر قرار گرفته و نتایچ یادگیری برنامه درسی را با یادگیری مستقیم مقایسه شده است. نتایج نشان میدهد که رویکرد مبتنی بر دروازه نسبتا سریع یاد میگیرد، در حالیکه رویکرد مبتنی بر آنیل کوانتومی تکرارهای آموزشی بیشتری برای یادگیری نیاز دارد. به طور مشابه، شاهد هستیم که رویکرد یادگیری تقویتی کلاسیک به مراحل آموزشی بیشتری برای یادگیری یک خط مشی نیاز دارد. در ابتدا، پاداش یافت شده برای هر سه رویکرد کم است، زیرا عامل به طور موثر یک پیادهروی تصادفی در محیط انجام میدهد. با یادگیری برنامه درسی، هنوز هیچ حالت جریمهای وجود ندارد، بنابراین تنها جریمه از برداشتن گامها ناشی میشود.
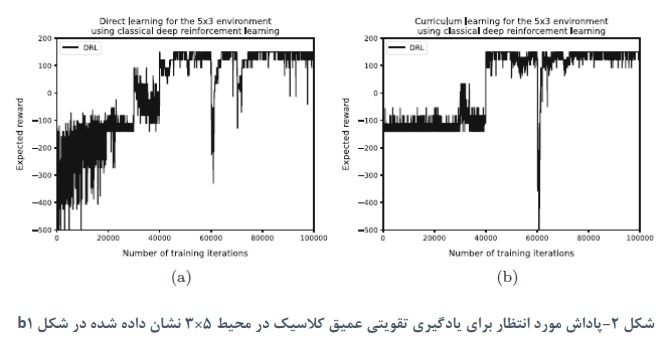
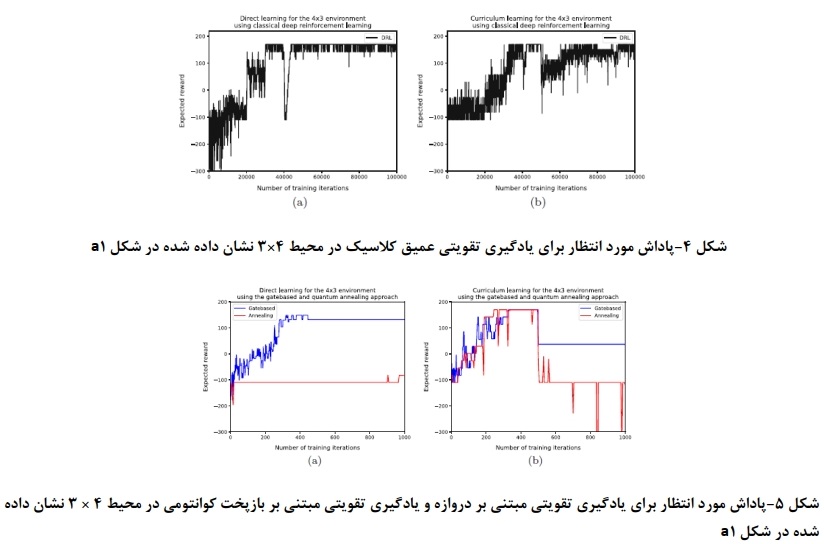
در همه نتایچ، همچنین تغییراتی را در پاداش یافت شده مشاهده میکنیم که ناشی از تصادفی بودن ذاتی در روش یادگیری است. برای هر دو رویکرد کوانتومی، این ترکیب حالت-عمل انتخابی برای در نظر گرفتن در آن تکرار است و برای رویکرد کلاسیک این مسیری است که برای کاوش انتخاب شده است. علاوه بر این، هنگامی که محیط را پیچیده می کنیم، شاهد کاهش پاداش یافت شده هستیم. شکل ۲ و ۳ نتایچ را برای محیط 5*3 نشان داده شده در شکل b۱ برای یادگیری مستقیم و یادگیری برنامه درسی نشان میدهد. رویکرد یادگیری تقویتی عمیق کلاسیک یک خط مشی خوب را میآموزد. با این حال، با یادگیری برنامه درسی، عملکرد پایدارتر است. هر دو رویکرد کوانتومی برای یادگیری برنامه درسی یکسان عمل میکنند و سیاست بهینه را نسبتا سریع یاد میگیرند. در یادگیری مستقیم، مشاهده میشود که هر دو رویکرد مسیر بهینه را نمیآموزند زیرا این پاداش ۱۵۰ : ۲۰۰ از هدف و ۵۰ - برای پنچ مرحله را تشکیل میدهد. رویکرد کوانتومی مبتنی بر دروازه در طول زمان بهبود مییابد، در حالیکه رویکرد مبتنی بر بازپخت کوانتومی به سرعت یک خط مشی را یاد میگیرد، اما پس از آن یادگیری را متوقف میکند. یک بازرسی بصری از خط مشی متوجه شد که مسیر یافت شده، عامل را قبل از رسیدن به حالت پایانی، از طریق حالت پنالتی هدایت میکند که در نتیجه یک پاداش کلی تقریبا صفر است. افت عملکرد در رویکردهای کلاسیک به احتمال زیاد ناشی از عدم اطمینان در فرایند یادگیری، یا از دو مسیری است که در ابتدا به یک اندازه خوب به نظر میرسند، اما یک مسیر دارای پاداش قابل توجهی کمتر است. انتظار میرود که دلیل مشابهی باعث افت عملکرد برای رویکردهای کوانتومی مبتنی بر گیت و مبتنی بر بازپخت شود.
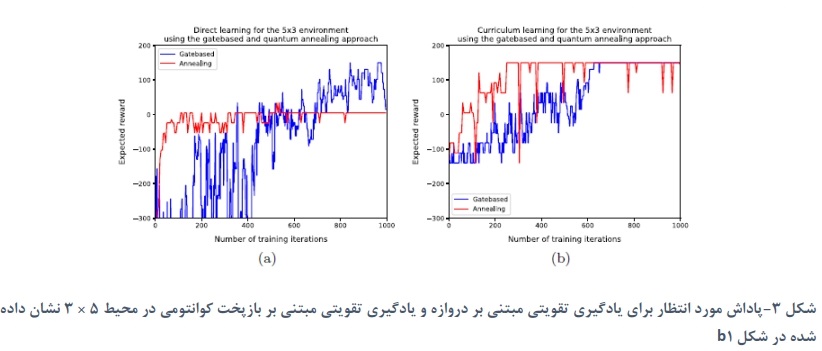
حال اگر محیط را پیچیده کنیم، رفتار متفاوتی را میبینیم. شکل ۳ و ۴ نتایچ را برای محیط ۴*۳ نشان داده شده در شکل a1 نشان میدهد. اگرچه این محیط کوچکتر است، اما پیچیدهتر از محیط ۵*۳ است، و از این رو، قبلاً انتظار عملکرد بدتری را داشتیم. هر دو رویکرد کوانتومی در ابتدا با یادگیری برنامه درسی سریعتر از یادگیری مستقیم یاد میگیرند. با یادگیری برنامه درسی، پس از معرفی حالتهای مجازات در محیط، شاهد کاهش شدید پاداش مورد انتظار هستیم. انتظار داریم که این امر از اولین مرحله یادگیری در یادگیری برنامه درسی که در آن خط مشیای آموخته میشود که در محیط پیچیدهتر کمتر از حد مطلوب است و حذف سریع ان بسیار سخت است، دنبال شود. یک بازرسی بصری از خط مشی به دست آمده توسط هر دو رویکرد کوانتومی تحت یادگیری برنامه درسی متوجه شد که تنها یک حالت عملکرد اشتباهی دارد که باعث میشود عامل به صورت دایرهای حرکت کند و پاداش کم پیدا شده را توضیح دهد. در تلاش برای غلبه بر این، عامل گاهی اوقا در حالت پنالتی قرار میگیرد، از این رو پاداش رویکرد مبتنی بر آنیل کوانتومی کاهش مییابد.
کمیکردن تاثیر اعمال تصادفی
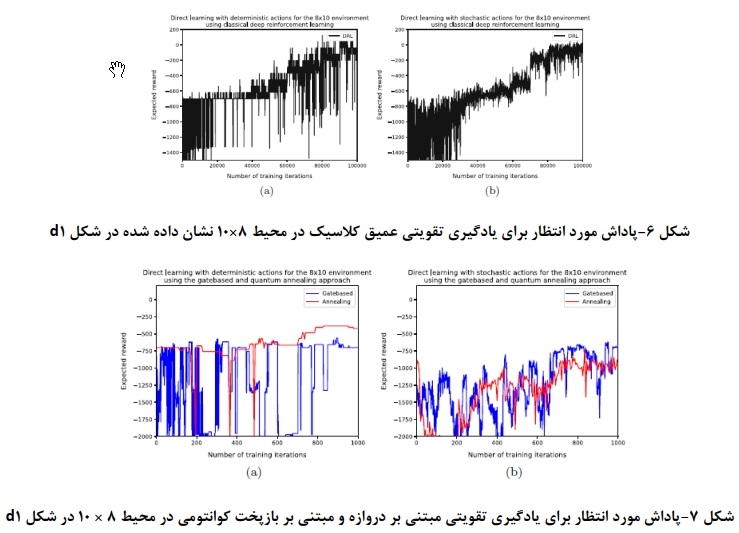
در این بخش، عملکرد رویکردهای خود را در تنظیمات تصادفی تحلیل میشود تا ببینیم آیا آنها میتوانند با آن همکاری کنند یا خیر بنابراین، دو دوره مستقل از یادگیری مستقیم را در نظر گرفتیم، یکی با اقدامات قطعی و دیگری با اقدامات تصادفی. این کار را برای هر یک از سه رویکرد انجام داده و پاداش مورد انتظار را در طول زمان مقایسه شده است. از آنجایی که عملکرد مطلق تحت کنشهای تصادفی کمتر است، عمدتاً عملکرد نسبی بین این دو را در نظر گرفته میشود. مدلها در ابتدا پاداش کمی پیدا میکنند، زیرا عامل به طور موثر یک پیادهروی تصادفی را انجام میدهد. برای برخی از محیطها، مدل در یافتن یک خطمشی خوب مشکل دارد و عملکرد در طول مرحله آموزش نسبتا ثابت میماند، به ویژه برای محیطهای بزرگتر که با هر یک از دو رویکرد کوانتومی ترکیب شدهاند. یکی دیگر از تاثیرات تصادفی این است که پاداش در طول زمان واریانس بیشتری را نسبت به اقدامات قطعی نشان میدهد. شکل b۶ و b۷ عملکرد رویکرد یادگیری تقویت عمیق کلاسیک و هر دو رویکرد کوانتومی را برای محیط 8*10 نشان میدهد. این محیط بزرگترین و پیچیدهترین محیط در نظر گرفته شده است. عملکرد با اقدامات تصادفی مشابه عملکرد با اقدامات قطعی برای هر سه رویکرد است. برای هر دو نسخه کوانتومی، پاداش مورد انتظار پایینتر شروع میشود، اما شاهد پیشرفتهایی به دلیل یادگیری هستیم که نشان میدهد پس از مراحل آموزشی کافی، پاداش انتظاری برای اقدامات قطعی و تصادفی همزمان خواهد شد. به عنوان آزمون نهایی، اثر ترکیبی دو پسوند در نظر گرفته میشود: یادگیری برنامه درسی با اقدامات تصادفی. رویهای که برای یادگیری برنامه درسی اعمال میشود به این صورت است که بعد از یک چهارم مراحل آموزشی، حالتهای مجازات را معرفی میکنیم. پس از نیمی از مرحله آموزش، اقدامات تصادفی با مقدار p بالا را معرفی میشود و پس از سه چهارم مراحل آموزش، مقدار p را کاهش میدهیم که منجر به تصادفی بیشتر در اقدامات میشود. تعداد مراحل آموزشی را برای هر یک از محیطهای در نظر گرفته شده دو برابر میکنیم.
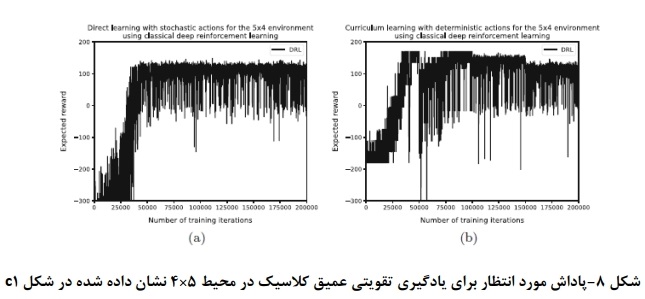
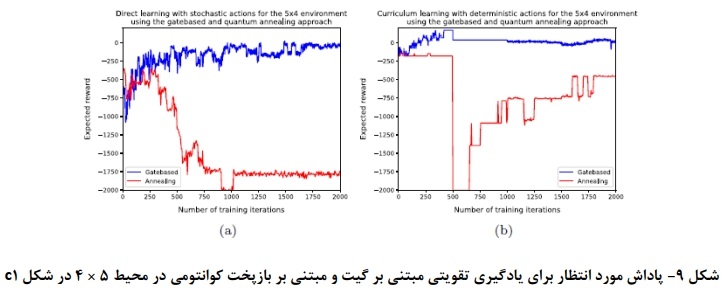
شکلهای a۸ و a۹ عملکرد رویکرد یادگیری تقویتی عمیق کلاسیک و دو رویکرد کوانتومی برای محیط ۴x۵ را نشان میدهند که در شکل C۱ نشان داده شده است. مشاهده میشود که رویکرد یادگیری تقویت عمیق کلاسیک به پاداشهای مشابهی میرسد، اما این کار را زودتر انجام میدهد. به طور مشابه، رویکرد مبتنی بر دروازه به عملکرد مشابهی برای هر دو استراتژی یادگیری میرسد، اما با یادگیری برنامه درسی، پاداش پایدارتر است. رویکرد مبتنی بر بازپخت کوانتومی هنگام استفاده از یادگیری برنامه درسی نسبت به یادگیری مستقیم، بهبود قابل توجهی را نشان میدهد، با این حال، عملکرد مطلق کمتر از دو رویکرد دیگر است. یک جنبه جالب این است که با یادگیری برنامه درسی، زمانی که محیط را پیچیده میکنیم، شاهد افت قابل توجهی در عملکرد هستیم. این افت نشان میدهد که خط مشی آموخته شده تاکنون برای محیطهای پیچیدهتر نا بهینه بوده است بنابراین، این رویکرد باید بخشی از سیاست این محیط جدید را دوباره یاد بگیرد.
بررسی عملکرد نتایج
در بخشهای قبل، نتایج آزمایشهای چندگانه برای رویکرد کلاسیک و دو رویکرد کوانتومی برای پیمایش شبکه ارائه شده است. تاثیر یادگیری برنامه درسی و تاثیر اقدامات تصادفی را بر عملکرد روی رویکردها در نظر گرفتیم. دریافتیم که در برخی از محیطها، دو رویکرد کوانتومی به مراحل آموزشی بسیار کمتری نسبت به رویکرد یادگیری تقویت عمیق کلاسیک برای دستیابی به عملکرد مشابه نیاز دارند. در محیطهای دیگر، عملکرد رویکردهای کوانتومی کمی عقبتر بود، با این حال، همچنان از تکرارهای آموزشی کمتری استفاده میکرد. یک راه حل ممکن، تنظیم بهتر فراپارامترها یا تغییر در تنظیمات یادگیری است. از لحاظ زمانی، هیچ مقایسهای بین رویکردهای مختلف نیست، زیرا رویکردهای کوانتومی شبیهسازی شده و از پشتوانههای سختافزاری مختلف برای این شبیهسازیها و نتایچ کلاسیک استفاده شده است. در نتیجه زمان اجرای آزمایشها غیرقابل مقایسه و کنار گذاشته شده است.
اولین بسط از مدلها یک تکنیک یادگیری متفاوت است: یادگیری برنامه درسی. با یادگیری برنامه درسی، به تدریج محیط را به امید یادگیری سریعتر پیچیده میشود. به استثنای محیط ۳x۴ هنگام استفاده از یادگیری برنامه درسی به جای یادگیری مستقیم، همگرایی سریعتر به یک خط مشی با پاداش مورد انتظار بالا را مشاهده میکنیم. مصنوعاتی که در محیطهای کوانتومی مشاهده میشود، زمانی که محیط را پیچیده میکنیم، افت شدید عملکرد است. انتظار داریم که دو رویکرد کوانتومی یک خط مشی را برای محیط ساده یاد بگیرند و در خارج کردن بخشهای بهینه این سیاست در محیط پیچیدهتر مشکل داشته باشند. یک راه حل برای این کار انتقال به یک محیط پیچیدهتر است، به محض اینکه یک سطح عملکرد معین به دست آید، نه پس از تعداد ثابتی از تکرارهای آموزشی. توسعه دوم اجازه اقدامات تصادفی انجام شده توسط عوامل را میداد. با برخی احتمالات، اقدامی متفاوت از آنچه در ابتدا در نظر گرفته شده بود انجام میشود. دریافتیم که برای هر رویکرد، عملکرد تحت کنشهای قطعی نزدیک به عملکرد در کنشهای تصادفی است. هنگام ترکیب هر دو پسوند، میبینیم که به ویژه رویکرد مبتنی بر بازپخت کوانتومی از استراتژی یادگیری برنامه درسی سود میبرد. دو رویکرد دیگر نهایی مشابهی را جهت عملکرد برای هر دو استراتزی یادگیری نشان میدهند. نکته قابل توجه تفاوت در یادگیری بین رویکرد یادگیری تقویتی عمیق کلاسیک و دو رویکرد کوانتومی است. رویکرد کلاسیک به یک عامل اجازه میدهد تا محیط را از حالت شروع بررسی کند و از کل مسیر طی شده برای بهروز رسانی خط مشی برای هر تکرار آموزشی استفاده کند. دو رویکرد کوانتومی تنها ترکیبهای تک حالت-عملی را در هر تکرار آموزشی در نظر میگیرند و سیاست را فقط بر اساس نتایچ آن ترکیب حالت-عمل بهروز میکنند.
نتیجه گیری
در این مقاله، دو رویکرد کوانتومی برای پیمایش شبکه با استفاده از یادگیری تقویتی، یک رویکرد مبتنی بر دروازه و یک رویکرد مبتنی بر آنیل کوانتومی در نظر گرفته شده است. مدلهای قبلی را با گنجاندن اقدامات تصادفی و استفاده از یک تکنیک یادگیری جدید به نام یادگیری برنامه درسی گسترش داده شده است. پاداش مورد انتظار یک خطمشی آموخته شده را با رویکرد کوانتومی با خط مشی آموخته شده با استفاده از یادگیری تقویت عمیق کلاسیک مقایسه و این کار را برای هر دو پسوند انجام شده است. متوجه شدیم که برای برخی از محیطها، رویکردهای کوانتومی سریعتر از رویکرد کلاسیک با ضریب تقریبا صد از نظر تعداد مراحل آموزشی، یاد میگیرند. برای محیطهای دیگر، تفاوت احتمالا کوچکتر است، زیرا عملکرد رویکردهای کوانتومی در سطح عملکرد رویکرد کلاسیک نبود. انتظار میرود که با بالغ شدن سختافزار کوانتومی، بتوانیم این آزمایشها را بر روی سختافزار کوانتومی با عملکرد مشابهی که در شبیهسازیها یافت میشود، اجرا کنیم. در نتیجه، معتقدیم که شکاف بین رویکرد کلاسیک و رویکردهای کوانتومی میتواند برای محیطهای پیچیدهتر و سختافزار کوانتومی بهبود یافته افزایش یابد.
همچنین تفاوت عملکرد بین یادگیری برنامه درسی و یادگیری مستقیم تجزیه و تحلیل شده است. در اولی، پیچیدگی محیط به تدریج افزایش مییابد، در دومی، محیط کامل به طور مستقیم ارائه میشود. دریافتیم که با یادگیری برنامه درسی، پاداش مورد انتظار بالاتر در همه موارد زودتر به دست میآید. رویکرد مبتنی بر بازپخت کوانتومی تفاوتهایی را در عملکرد بین محیطهای مختلف نشان داد. همچنین تاثیر اقدامات تصادفی انجام شده توسط عوامل را در نظر گرفته شده که در آن عوامل فقط با احتمال کمی قدم مورد نظر را بر میدارند و در غیر این صورت به یکی از حالات مجاور حرکت میکنند. مشاهده میشود که مدلهای مورد مقایسه با کنشهای تصادفی، تحت اعمال قطعی به همان اندازه خوب عمل میکنند. یادگیری برنامه درسی در هنگام در نظر گرفتن اقدامات تصادفی پتانسیل خود را نشان داد، زیرا رویکردها میتوانستند قبل از حرکت به سمت اقدامات تصادفی پیچیدهتر، یک خطمشی معقول را تحت اقدامات قطعی بیاموزند.
توجه داشته باشید که مقایسه عملکرد رویکردهای ما با کارهای قبلی، مانند دشوار است. در کار قبلی، برداشتن یک گام هزینهای نداشت. با این حال، هزینه اضافی برداشتن یک قدم را اضافه شده است، در نتیجه مسیرهای کوتاهتر را نسبت به مسیرهای طولانیتر ترجیح دادیم. در نتیجه، پاداش یافت شده در برخی از محیطها کم به نظر میرسد، در حالیکه خط مشی نزدیک به بهینه است. در بیشتر موارد، این پاداش کمتر ناشی از یک یا چند حالت با اقدامات نادرست اختصاص داده شده به آن است که باعث میشود عوامل در دایرهها سرگردان شوند. تغییرات در استراتژی یادگیری برنامه درسی نیز میتواند عملکرد مدلها را با یادگیری سریعتر یک خط مشی بهینه افزایش دهد. در این مقاله، فقط پس از تعداد ثابتی از مراحل اموزشی، محیط پیچیده شده است. در برخی موارد، این امر منجر به یادگیری سریع سیاست و تقویت این سیاست بهینه شد. سیاستی که بدین ترتیب آموخته میشود میتواند در محیطهای پیچیدهتر نا بهینه یا حتی بد باشد. ثابت شد که بهروز رسانی خط مشی برای برخی از محیطها سخت است. یک استراتژی یادگیری برنامه درسی بهبود یافته، پیچیده کردن محیط پس از دستیابی به عملکرد معین است. با این حال، تعیین آستانه عملکرد متناظر در زمانی که محیط را پیچیده میکند، نیازمند دانش بیشتری از محیط در نظر گرفته شده واقعی است. این دانش مورد نیاز با هدف اصلی برای استفاده از مدلها در تنظیمات عملیاتی با ورودی دستی کاربر محدود در تضاد است.
و در آخر:
در این قسمت توضیحاتی آموزنده در مورد بررسی الگوریتمهای پردازش کوانتومی در هوش مصنوعی و یادگیری ماشین گذاشته شد. در آینده مطالب بیشتری را در اختیار شما قرار خواهیم داد، با آرزوی بهترینها برای شما خواننده محترم.
منابع:
حسین کاظمی، "بررسی الگوریتمهای پردازش کوانتومی در هوش مصنوعی و یادگیری ماشین".

دیدگاه خود را بنویسید