




تاریخچه داده کاوی:
اخیراً دادهکاوی موضوع بسیاری از مقالات، کنفرانسها و رسالههای علمی شده است، اما این واژه تا اوایل دهه 60 مفهومی نداشت و به کار برده نمیشد. در دهه 60 و پیش از آن زمینههایی برای ایجاد سیستمهای جمع آوری و مدیریت دادهها ایجاد شد و تحقیقاتی در این زمینه انجام پذیرفت که منجر به معرفی و ایجاد سیستمهای مدیریت پایگاه دادهها گردید. ایجاد و توسعه مدل های دادهای برای پایگاه سلسله مراتبی، شبکهای و به خصوص رابطهای در دهه 70، منجر به معرفی مفاهیمی همچون شاخص گذاری و سازماندهی دادهها و در نهایت ایجاد زبان پرسش SQL در اوایل دهه 80 گردید تا کاربران بتوانند گزارشات و فرمهای اطلاعاتی مورد نظر خود را، از این طریق ایجاد نمایند. توسعه سیستم های پایگاهی پیشرفته در دهه 80 و ایجاد پایگاههای شیء گرا، کاربرد گرا و فعال باعث توسعه همه جانبه و کاربردی شدن این سیستمها در سراسر جهان گردید.
تعاریف داده کاوی:
داده کاوی تعاریف مختلفی دارد که در زیر بیان شده است:
1) داده کاوی مرحلهای از فرآیند کشف دانش است که با کمک الگوریتمهای خاص داده کاوی و با کارایی قابل قبول محاسباتی، الگوها یا مدل ها را در دادهها پیدا میکند.
2) داده کاوی، آمار در مقیاس و سرعت است.
فرآیند کشف دانش/ داده کاوی:
بر اساس دیدگاهی که داده کاوی را بخشی از فرآیند کشف دانش می دانند، کشف دانش شامل مراحل متعددی مطابق با شکل زیر است. همچنین جزئیات مربوط به فرآیند KDD در زیر آورده شده است:
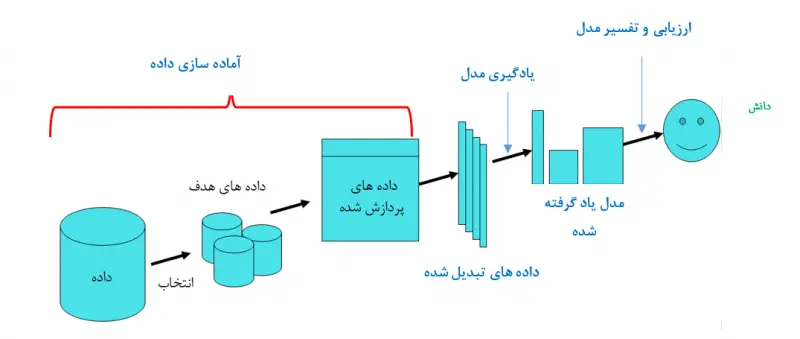
1) درک کامل حوزه کاربرد:
شامل درک دانش پیشین مرتبط، اهداف کاربر نهایی و غیره می باشد.
2) ایجاد مجموعه داده های هدف:
انتخاب مجموعه دادهها یا تمرکز روی زیرمجموعهای از متغییرها یا نمونههای داده که قرار است روی آنها اکتشاف انجام شود، ایجاد مجموعه دادههای هدف نامیده میشود.
3) پیش پردازش یا پاکسازی داده:
عملیات مقدماتی مثل حذف اغتشاش یا نقاط پرت، جمع کردن اطلاعات لازم برای مدل کردن یا مقابله با اغتشاش، تصمیم گیری در مورد چگونگی رفتار با دادههای مفقوده، در نظر گرفتن توالی زمانی و تغییرات شناخته شده در اطلاعات، پاکسازی دادهها نامیده میشود.
4) کاهش دادهها و تصویر کردن آنها:
یافتن مشخصههای مفید برای داده بسته به هدف وظیفه و استفاده از روشهای کاهش بُعد یا تبدیل برای کاهش تعداد موثر متغییرهای مورد نظر یا پیدا کردن نمود مناسب و معادل دادهها، کاهش دادهها نامیده میشود.
5) انتخاب عملیات داده کاوی:
تصمیم گیری در مورد هدف فرآیند KDD که می تواند دسته بندی، رگرسیون، خوشه بندی یا غیره باشد.
6) انتخاب روش های داده کاوی:
این گام شامل انتخاب روش های جستجوی الگوها در دادهها بوده و شامل انتخاب مدلها و پارامترهای مناسب تطابق یک روش داده کاوی خاص با معیارهای کلی فرآیند KDD است.
7) داده کاوی برای استخراج الگوها / مدل ها:
در این گام به جستجوی الگوهای مورد نظر به یک یا چند شکل خاص (قواعد یا درختان دسته بندی، رگرسیون، خوشه بندی و مانند آن) پرداخته می شود.
8) تفسیر و ارزیابی الگوها / مدل ها:
لازم است الگوها و مدل های مختلف به منظور استفاده بعدی مورد ارزیابی و تفسیر قرار گیرند.
9) پایش یا تثبیت دانش کشف شده:
ترکیب این دانش با سیستم اجرایی یا حداقل مستند سازی و گزارش آن به گروههای علاقه مند، تثبیت دانش یا پایش نامیده می شود. این کار شامل بررسی و حل تضادهای بالقوه این دانش با دانشهای مورد قبول (یا کشف شده) پیشین می باشد. ممکن است میان هر قدم و قدم قبلی آن عملاً نوعی تکرار رخ دهد.
انواع داده های مورد استفاده در داده کاوی:
یک مجموعه داده از اشیاء داده تشکیل شده است. نام های دیگر شیء داده عبارتند از: رکورد، نقطه، بردار، الگو، واقعه، مورد، نمونه، مشاهده و یا موجودیت. هر شیء داده نیز با تعدادی ویژگی توصیف می شود که خصوصیات اصلی آن شیء را بیان می کنند. نام های دیگر ویژگی عبارتند از متغییر، خصیصه، فیلد، مشخصه و یا بُعد.
ویژگی های کمی و کیفی:
یک ویژگی خاصیتی از یک شیء داده می باشد که ممکن است از شیئی یه شیئی دیگر یا از زمانی به زمان دیگر متفاوت باشد. یک راه ساده و مفید برای تعیین نوع ویژگی، تشخیص خواص اعداد متناظر با آن ویژگی است. معمولاً خواص زیر برای توصیف ویژگیها استفاده می شود.
1) تمایز = و #
2) ترتیب >، <، =>، =<
3) جمع پذیری + و –
4) ضرب * و /
با توجه به این خواص می توان 4 نوع ویژگی تعریف کرد: اسمی، رتبهای یا ترتیبی، فاصلهای یا بازهای و نسبتی یا نسبی.
ویژگی های گسسته و پیوسته:
راه دیگر تفکیک ویژگی ها، بر حسب تعداد مقادیری است که می توانند بگیرند.
1) گسسته: ویژگی گسسته، مجموعه مقادیر محدود و یا نامحدود قابل شمارش دارد. ویژگیهای گسسته معمولاً با متغییرهای صحیح نمایش داده می شوند. ویژگی هایی دودویی حالت خاصی از ویژگی های گسستهاند که فقط دو مقدار مانند 0 و 1 دارند. ویژگی های دودویی اغلب به شکل بولی یا متغییرهای دارای دو مقدار 0 و 1 بیان می شوند.
2) پیوسته: ویژگی پیوسته دارای مقادیری از نوع اعداد حقیقی است. ویژگی های پیوسته نوعاً با متغییرهای اعشاری با دقت محدود بیان می شوند.
به طور نظری، هر کدام از انواع مقیاس های اندازه گیری (اسمی، رتبه ای، فاصله ای و نسبی) میتوانند با هر یک از انواع مقادیر عددی (دودویی، گسسته و پیوسته) ترکیب شوند.
کاربرد های داده کاوی (KDD):
1) اطلاعات کسب و کار
2) تحلیل داده های بازاریابی و فروش
3) تحلیل سرمایه گذاری
4) تایید وام
5) تشخیص تقلب
6) اطلاعات ساخت و تولید
7) کنترل و زمانبندی
8) مدیریت شبکه
9) تحلیل نتایج آزمایشات فنی
10) اطلاعات علمی
11) فهرست برداری تحقیقات مربوط به آسمان
12) پایگاه داده های پزشکی
13) زلزله یابی در زمین شناسی
14) اطلاعات شخصی
چالش های داده کاوی:
1) پایگاه داده بزرگتر: پایگاه داده با صدها فیلد و جدول، میلیون ها رکورد و اندازه های چند میلیارد بایتی کاملاً متداول هستند و استفاده از پایگاه داده ترابایتی معمول می شود.
2) بُعد زیاد: نه تنها اغلب تعداد زیادی رکورد در پایگاه داده وجود دارد بلکه تعداد زیادی فیلد (ویژگی، متغییر) ممکن است موجود باشند، بنابراین مسئله دارای ابعاد زیادی است. یک مجموعه داده با بُعد بالا مشکلزا است زیرا فضای جستجو نیاز به تلاش برای استقراء مدل را به طور فزاینده ای بزرگ می کند. به علاوه این مشکل، یافتن شانسیِ الگوهای بدلی و جعلی را افزایش میدهد. چاره این مشکل استفاده از روشهای کاهش بُعد موثر و استفاده از دانش پیشین برای تشخیص متغییرهای نامربوط است.
3) پیش پردازش: وقتی الگوریتم به دنبال بهترین پارامترهای یک مدل خاص با استفاده از مجموعه محدودی داده می گردد، ممکن است دادهها را پیش پردازش کند که منجر به عملکرد ضعیف روی دادههای آزمون شود.
4) تشخیص معنادار بودن آماری: وقتی سیستم در جستجوی مدل های متعددی است این مشکل (که مرتبط به پیش پردازش است) رخ می دهد. یک راه غلبه بر این مشکل استفاده از روش هایی است که آمار آزمون را به عنوان تابعی از جستجو تنظیم می کنند.
5) داده ها و دانش در حال تغییر: دادههای سریعاً در حال تغییر و بی ثبات ممکن است الگوهای کشف شده قبلی را بی اعتبار کنند. به علاوه متغییرهای اندازه گیری شده در یک پایگاه داده ممکن است با اندازه گیریهای جدید در طول زمان، اصلاح شده حذف و یا افزایش یابند. راه حلهای ممکن عبارتند از: روشهای تدریجی برای به هنگام کردن الگوها و برخورد با تغییر به عنوان یک فرصت کشف (با به کار بردن آن به عنوان راهنمایی برای جستجوی خود الگوهای متغییر).
6) داده مفقوده و مغشوش: این مشکل به خصوص در پایگاه دادههای تجاری حاد است. اگر در پایگاه داده از ابتدا با هدف کشف دانش طراحی نشده باشد ممکن است فاقد برخی از ویژگیهای مهم باشد. راه حل ممکن به کار بردن استراژدی های آماری پیچیده تر برای تشخیص متغییرها و وابستگی های مخفی است.
7) روابط پیچیده بین فیلد ها: ویژگی ها یا مقادیر با ساختار سلسه مراتبی، روابط میان ویژگی ها و نیز انواع روشهای پیچیده نمایش دانش، نیاز به الگوریتم هایی دارند که بتوانند به طور موثر از این اطلاعات استفاده کند. الگوریتمهای داده کاوی به طور تاریخی برای رکورد های (ویژگی – مقدار) ساده توسعه یافتهاند. البته روش های جدیدی برای عمل روی رابطه بین متغییرها در حال توسعهاند.
8) قابل درک بودن الگوها: در بسیاری از کاربردهای داده کاوی، اینکه کشفیات برای انسان قابل فهمتر شوند، بسیار مهم است. راههای ممکن عبارتند از: نمایش گرافیکی، ساختاربندی قواعد با گراف های جهتدار غیردوری، به کارگیری زبان طبیعی و فنون مصورسازی داده و دانش.
9) تعامل با کاربر و دانش پیشین: بسیاری از روشها و ابزارهای فعلی KDD واقعاً تعاملی نیستند و نمیتوانند به آسانی دانش پیشین درباره یک مسئله (به جز در موارد ساده) در نظر بگیرند. استفاده از دانش حوزه مورد مطالعه در همه مراحل فرآیند KDD مهم است.
10) تلفیق با سیستم های دیگر: یک سیستم اکتشاف دانش ممکن است به تنهایی مفید نبوده و بهتر باشد با سایر سیستمها تلفیق یا یکپارچه شود. نمونههای تلفیق عبارتند از: تلفیق با DBMS (از طریق رابط پرسوجو)، تلفیق با صفحه گستردهها و ابزار های مصورسازی و همچنین میتوان حسگرهایی را برای قرائت بلادرنگ دادهها با این سیستمها تلفیق نمود.

یادگیری ماشین:
برای یادگیری ماشین تعریف سادهای را می توان بیان کرد به این صورت که: به هر برنامهی کامپیوتری که بتواند کارائی خود را در انجام بعضی وظایف یا کسب تجربه بهبود ببخشد، یادگیری ماشین گویند.
یادگیری با نظارت:
یادگیری با نظارت یک روش عمومی در یادگیری ماشین است که در آن به یک سیستم، مجموعهای از جفتهای ورودی - خروجی ارائه شده و سیستم تلاش می کند تا تابعی از ورودی به خروجی را فرا گیرد. یادگیری تحت نظارت نیازمند تعدادی داده ورودی به منظور آموزش است. با این حال رده ای از مسائل وجود دارند که خروجی مناسب که یک سیستم یادگیری تحت نظارت نیازمند آن است، برای آنها موجود نیست. این نوع از مسائل چندان قابل جوابگویی با استفاده از یادگیری تحت نظارت نیستند. یادگیری تقویتی مدلی برای مسائلی از این قبیل فراهم می آورد.
یادگیری بدون نظارت:
این نوع یادگیری زمانی رخ می دهد که ماشین با استفاده از دادههایی، آموزش میبیند که هیچ گونه برچسب گذاری روی آن انجام نشده باشد. در این روش هرگز به الگوریتمها گفته نمیشود که دادهها نمایانگر چه هستند. بنابراین در این نوع یادگیری نیازی به حضور ناظر یا خبره نیست.
نکته کلیدی در مورد یادگیری نظارت نشده آن است که پس از پردازش اطلاعات بدون برچسب، تنها کافی است که یک نمونه از دادههای برچسب گذاری شده در اختیار الگوریتم یادگیری قرار داده شده است تا کارائی کامل پیدا کند.
مفاهیم دسته بندی:
بسیاری از روش های دسته بندی در علومی مانند: یادگیری ماشین، بازشناسی الگو و آمار کاربرد دارند. دستهبندی برای تخصیص یک برچسب به مجموعهای از دادهها که هنوز دسته بندی نشدهاند، استفاده میشود. پس از آن دادهها براساس ویژگی هایشان به دسته هایی که نام آنها از قبل مشخص میباشد، تخصیص داده میشوند. دسته بندی برای یادگیری قواعد و یا ساختن مدلی به منظور پیش بینی دستهی دادههای جدید به کار می رود. دادههای مورد استفاده برای ساختن مدل، دادههای آموزش یا دادههای ترتیب مدل نامیده میشوند.
روش های مختلف دسته بندی:
روش های زیادی برای دسته بندی وجود دارد که از آن جمله می توان به موارد ذیل اشاره کرد:
1) بیز ساده و شبکه های بیزین
2) نزدیک ترین همسایگی
3) شبکه های عصبی
4) درخت تصمیم
5) رگرسیون (خطی، غیرخطی)
روش دسته بندی درخت تصمیم:
ساختار درخت تصمیم در یادگیری ماشین، یک مدل پیش بینی کننده میباشد که حقایق مشاهده شده در مورد یک پدیده را به استنتاج هایی در مورد مقدار هدف آن مقدار پدیده نقش میکند. تکنیک یادگیری ماشین برای استنتاج یک درخت تصمیم از دادهها، یادگیری درختتصمیم نامیده میشود که یکی از رایجترین روشهای دادهکاوی است. هر گرهی داخلی متناظر یک متغییر و هر کمان به یک فرزند، نمایانگر یک مقدار ممکن برای آن متغییر است. یک گرهی بزرگ، با داشتن مقادیر متغییرها که با مسیری از ریشهی درخت تا آن گرهی بزرگ بازنمایی میشود، مقدار پیش بینی شدهی متغییر هدف را نشان میدهد. یک درخت تصمیم ساختاری را نشان میدهد که برگها نشان دهندهی دسته بندی و شاخهها ترکیبات فصلی صفاتی که منتج به این دستهها را بازنمایی میکنند. یادگیری یک درخت تصمیم می تواند با تفکیک کردن یک مجموعهی منبع به زیرمجموعههایی براساس یک تست مقدار صفت انجام شود. این فرآیند به شکل بازگشتی در هر زیرمجموعهی حاصل از تفکیک تکرار می شود. عمل بازگشت زمانی کامل می شود که تفکیک بیشتر سودمند نباشد یا بتوان یک دستهبندی را به همهی نمونههای موجود در زیرمجموعهی به دست آمده اعمال کرد.
درختان تصمیم قادر به تولید توصیفات قابل درک برای انسان، از روابط موجود در یک مجموعه دادهای هستند و میتوانند برای وظایف دستهبندی و پیش بینی به کار روند. این تکنیک به شکل گستردهای در زمینههای مختلفی همچون تشخیص بیماری، دسته بندی گیاهان و استراژدیهای بازاریابی مشتری به کار رفته است. این ساختار تصمیم گیری میتواند به شکل تکنیکهای ریاضی و محاسباتی که به توصیف، دستهبندی و عام سازی یک مجموعه داده کمک می کنند، نیز معرفی شوند. انواع صفات در درخت تصمیم به دو نوع صفات دستهای و صفات حقیقی بوده که صفات دستهای، صفاتی هستند که دو یا چند مقدار گسسته میپذیرند (یا صفات سمبلیک) در حالی که صفات حقیقی مقادیر خود را از مجموعهی اعداد حقیقی میگیرند.
انواع روش های هرس کردن:
انواع روش های هرس کردن عبارتند از:
1) روش هرس از قبل: روش هایی که در آنها، رشد درخت قبل از اینکه به نقطهای برسد که کاملاً مثال های آموزشی را دستهبندی کند متوقف میشوند. (مشکل این روشها در تعیین زمان توقف رشد درخت است.)
2) روش هرس بعدی: روش هایی که اجازه میدهند درخت کاملاً ساخته شود و دادهها را Over Fit کند، سپس آن را هرس می کنند. (این روشها در عمل موفقتر هستند.)
روش نزدیکترین همسایگی:
الگوریتم نزدیکترین همسایگی از سه گام زیر تشکیل شده است:
1) محاسبه فاصله نمونه ورودی با تمام نمونه های آموزشی
2) مرتب کردن نمونه های آموزشی براساس فاصله و انتخاب K همسایه نزدیکتر
3) استفاده از دستهای که اکثریت را در همسایه های نزدیک به عنوان تخمینی برای دستهی نمونه ورودی دارد.
گام اول در روش نزدیکترین همسایگی این است که باید فاصله نمونه ورودی با تمام نمونههای آموزشی محاسبه شود. گام دوم الگوریتم باید K همسایه نزدیکتر را انتخاب کند. نهایتاً در گام سوم، الگوریتم باید دستهای را که حائز اکثریت در بین همسایه هاست به عنوان دستهی نمونهی جدید در نظر بگیرد. اگرچه روش نزدیکترین همسایگی، روش ساده و موثری است ولی سرعت کمی دارد.
شبکه های بیزین:
شبکه های بیزین وابستگی های شرطی بین متغییرها (ویژگیها) را شرح می دهد. با استفاده از این شبکهها دانش قبلی در زمینه وابستگی بین متغییرها با دادههای آموزش مدل و دسته بندی، ترکیب میشوند. در اینجا یک کلاس از طبقهبندی شبکه بیزین را شرح خواهیم داد.
الگوریتم بیز ساده:
یک شبکه بیزین، بیز ساده ساختار سادهای است که در آن نود کلاس به عنوان والد بقیه نود هاست. در ساختار بیز ساده هیچ ارتباط دیگری مجاز نیست و فرض میشود که همه ویژگیها مستقل از یکدیگر هستند. بیز ساده در دستهبندیهایی که مجموعه داده وسیعی ندارند، استفاده نمیشود. این دسته بندی در سال 1702-1761 توسط توماس بیز، به نام قضیه بیز پیشنهاد و نام گذاری شد. در سال های اخیر تلاش زیادی برای بهبود دستهبندی بیز ساده در زمینههای زیر صورت گرفته است: انتخاب زیرمجموعهای از ویژگیها و تخفیف یافتن استقلال فرض شده. کارائی دسته بندی بیز ساده حتی اگر استقلال فرض شده بین ویژگیها در بیشتر مجموعههای داده غیر واقعی باشد، خوب است. استقلال بین ویژگیها هر ارتباطی را بین آنها نادیده میگیرد. توسعه ساختار بیز ساده برای نمایش صریح وابستگی متغییرها روشی برای غلبه بر محدودیت های بیز ساده است.
نرم افزار های داده کاوی:
تا به امروز نرم افزارهای تجاری و آموزشی فراوانی برای داده کاوی در حوزههای مختلف دادهها به دنیای علم و فناوری عرضه شدهاند. هر یک از آنها با توجه به نوع اصلی دادههایی که مورد کاوش قرار میدهند، روی الگوریتمهای خاصی متمرکز شدهاند. مقایسه دقیق و علمی این ابزارها باید جنبههای متفاوت و متعددی مانند تنوع و فرمت دادههای ورودی، حجم ممکن برای پردازش دادهها، الگوریتمهای پیاده سازی شده، روشهای ارزیابی نتایج، روش های مصور سازی، روش های پیش پردازش دادهها، واسط های کاربر پسند، پلتفرمهای سازگار برای اجرا، قیمت و در دسترس بودن نرم افزار صورت میگیرد.

نرم افزار رپیدماینر:
این نرم افزار یک ابزار داده کاوی متن باز است که با زبان جاوا نوشته شده است و از سال 2001 تا به حال، توسعه داده شده است. در این نرم افزار سعی تیم توسعه دهنده، بر آن بوده است که تا حد امکان تمامی الگوریتمهای رایج داده کاوی و همچنین یادگیری ماشین پوشش داده شوند. به گونهای که حتی این امکان برای نرم افزار فراهم شده است تا بتوان سایر ابزارهای متن باز دادهکاوی را نیز به آن الحاق نمود. رابط گرافیکی شکیل و کاربر پسند نرم افزار نیز آن را یک سر و گردن بالاتر از سایر ابزارهای رقیب قرار می دهد. از نقاط قوت نرم افزار میتوان به موارد زیر اشاره کرد.
1) ارائه گزارش و رونوشت از مراحل اجرای الگوریتم
2) ظاهر پرداخته و آراسته
3) نمای گرافیکی خوب
4) قابلیت تطابق با فایل های خروجی بسیاری از نرم افزارها مانند: اکسل
5) امکان تصحیح و خطایابی بسیار صریح
و در آخر:
در این قسمت توضیحاتی آموزنده در مورد داده کاوی و نرم افزار رپیدماینر گذاشته شد. در آینده مطالب بیشتری را در اختیار شما قرار خواهیم داد، با آرزوی بهترینها برای شما خواننده محترم.
منابع:
بیرانوند، صبا، (1393)، بررسی روش های مبتنی بر یادگیری ماشین در تخمین هزینه نرمافزار، گزارش سمینار کارشناسی ارشد، دانشکده مهندسی برق و کامپیوتر، یزد، تیر.
هژبر، ابراهیم، (1393)، دادهکاوی – مفاهیم و کاربرد، پروژه کارشناسی نرمافزار، دانشگاه آزاد اسلامی، ورزقان.
غضنفری، محمد، علیزاده، سمیه، تیمور پور، بابک، (1387)، دادهکاوی و کشف دانش، دانشگاه علم و صنعت ایران، تهران.
عزیزی، لعبت، (1385)، یادگیری درختهای تصمیم، گزارش پژوهش در مورد یادگیری ماشین، امیر کبیر، تهران، خرداد.