





تاریخچه شبکههای عصبی مصنوعی
از قرن نوزدهم به طور همزمان اما جداگانه از سویی نروفیزیولوزیستها سعی کردند سیستم یادگیری و تجزیه و تحلیل مغز را کشف کنند، و از سوی دیگر ریاضیدانان تلاش کردند تا مدل ریاضی بسازند، که قابلیت فراگیری و تجزیه و تحلیل عمومی مسائل را دارا باشد. اولین کوششها در شبیهسازی با استفاده از یک مدل منطقی توسط مک کلوک و والتر پیتز انجام شد که امروزه بلوک اصلی سازنده اکثر شبکههای عصبی مصنوعی است. این مدل فرضیههایی در مورد عملکرد نورونها ارائه میکند. عملکرد این مدل مبتنی بر جمع ورودیها و ایجاد خروجی است. چنانچه حاصل جمع ورودیها از مقدار آستانه بیشتر باشد اصطلاحا نورون برانگیخته میشود. نتیجه این مدل اجرای توابع ساده مثل AND و OR بود.
نه تنها نروفیزیولوژیستها بلکه روانشناسان و مهندسان نیز در پیشرفت شبیهسازی شبکههای عصبی تاثیر داشتند. در سال ۱۹۵۸ شبکه پرسپترون توسط روزنبلات معرفی گردید. این شبکه نظیر واحدهای مدل شده قبلی بود. پرسپترون دارای سه لایه میباشد، به همراه یک لایه وسط که به عنوان لایه پیوند شناخته شدهاست. این سیستم میتواند یاد بگیرد که به ورودی داده شده خروجی تصادفی متناظر را اعمال کند. سیستم دیگر مدل خطی تطبیقی نورون میباشد که در سال ۱۹۶۰ توسط ویدرو و هاف (دانشگاه استنفورد) به وجود آمد که اولین شبکههای عصبی به کار گرفته شده در مسائل واقعی بودند. Adalaline یک دستگاه الکترونیکی بود که از اجزای سادهای تشکیل شده بود، روشی که برای آموزش استفاده میشد با پرسپترون فرق داشت.
در سال ۱۹۶۹ میسکی و پاپرت کتابی نوشتند که محدودیتهای سیستمهای تک لایه و چند لایه پرسپترون را تشریح کردند. نتیجه این کتاب پیش داوری و قطع سرمایهگذاری برای تحقیقات در زمینه شبیهسازی شبکههای عصبی بود. آنها با طرح اینکه طرح پرسپترون قادر به حل هیچ مساله جالبی نمیباشد، تحقیقات در این زمینه را برای مدت چندین سال متوقف کردند.
با وجود اینکه اشتیاق عمومی و سرمایهگذاریهای موجود به حداقل خود رسیده بود، برخی محققان تحقیقات خود را برای ساخت ماشینهایی که توانایی حل مسائلی از قبیل تشخیص الگو را داشته باشند، ادامه دادند. از جمله گراسبگ که شبکهای تحت عنوان Avalanch را برای تشخیص صحبت پیوسته و کنترل دست ربات مطرح کرد. همچنین او با همکاری کارپنتر شبکههای ART را بنانهادند که با مدلهای طبیعی تفاوت داشت. اندرسون و کوهونن نیز از اشخاصی بودند که تکنیکهایی برای یادگیری ایجاد کردند. ورباس در سال ۱۹۷۴ شیوه آموزش پس انتشار خطا را ایجاد کرد که یک شبکه پرسپترون چندلایه البته با قوانین نیرومندتر آموزشی بود.
پیشرفتهایی که در سال ۱۹۷۰ تا ۱۹۸۰ بدست آمد برای جلب توجه به شبکههای عصبی بسیار مهم بود. برخی فاکتورها نیز در تشدید این مساله دخالت داشتند، از جمله کتابها و کنفرانسهای وسیعی که برای مردم در رشتههای متنوع ارائه شد. امروز نیز تحولات زیادی در تکنولوژی ANN ایجاد شدهاست.
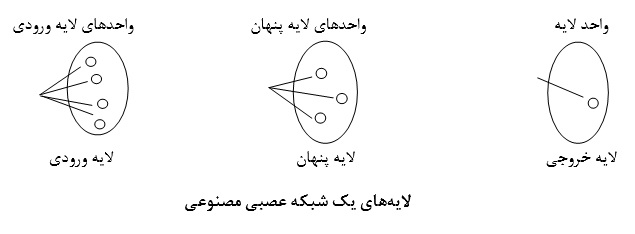
شبکه عصبی چیست؟
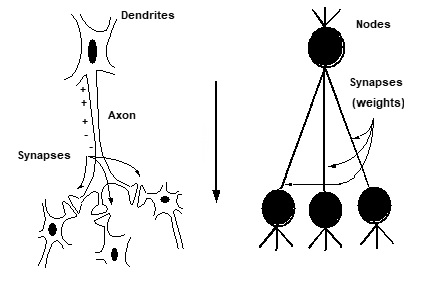
روشی برای محاسبه است که بر پایه اتصال به هم پیوسته چندین واحد پردازشی ساخته میشود. شبکه از تعداد دلخواهی سلول یا گره یا واحد یا نرون تشکیل میشود که مجموعه ورودی را به خروجی ربط میدهند.
شبکه عصبی چه قابلیتهایی دارد؟
- محاسبه یک تابع معلوم
- تقریب یک تابع ناشناخته
- شناسائی الگو
- پردازش سیگنال
- یادگیری انجام موارد فوق
شبکه های عصبی در مقایسه با کامپیوترهای سنتی
یک شبکه عصبی به طور کلی با یک کامپیوتر سنتی در موارد زیر تفاوت دارد :
1. شبکههای عصبی دستورات را به صورت سری اجرا نکرده، شامل حافظهای برای نگهداری داده و دستورالعمل نیستند.
2. به مجموعهای از ورودیها به صورت موازی پاسخ میدهند.
3. بیشتر با تبدیلات و نگاشتها سروکار دارند تا الگوریتمها و روشها.
4. شامل ابزار محاسباتی پیچیده نبوده، از تعداد زیادی ابزارساده که اغلب کمی بیشتر از یک جمع وزن دار را انجام میدهند، تشکیل شدهاند.
شبکههای عصبی شیوهای متفاوت برای حل مسئله دارند. کامپیوترهای سنتی از شیوه الگوریتمی برای حل مسئله استفاده میکنند که برای حل مسئله مجموعهای از دستورالعملهای بدون ابهام دنبال میشود. این دستورات به زبان سطح بالا و سپس به زبان ماشین که سامانه قادر به تشخیص آن میباشد تبدیل میشوند. اگر مراحلی که کامپیوتر برای حل مسئله باید طی کند از قبل شناخته شده نباشند و الگوریتم مشخصی وجود نداشته باشد، سامانه توانایی حل مسئله را ندارد. کامپیوترها میتوانند خیلی سودمندتر باشند اگر بتوانند کارهایی را که ما هیچ پیش زمینهای از آنها نداریم انجام دهند. شبکههای عصبی و کامپیوترها نه تنها رقیب هم نیستند بلکه میتوانند مکمل هم باشند. کارهایی وجود دارند که بهتر است از روش الگوریتمی حل شوند و همین طور کارهایی وجود دارند که جز از طریق شبکه عصبی مصنوعی قابل حل نمیباشند و البته تعداد زیادی نیز برای بدست آوردن بازده حداکثر، از ترکیبی از روشهای فوق استفاده میکنند. به طور معمول یک کامپیوتر سنتی برای نظارت بر شبکه عصبی استفاده میشود. شبکههای عصبی معجزه نمیکنند، اگر به طور محسوس استفاده شوند کارهای عجیبی انجام میدهند.
مسائل مناسب برای یادگیری شبکه های عصبی
1. خطا در داده های آموزشی وجود داشته باشد. مثل مسائلی که داده های آموزشی دارای نویز حاصل از دادهای سنسورها نظیر دوربین و میکروفن ها هستند.
2. مواردی که نمونه ها توسط مقادیر زیادی زوج ویژگی-مقدار نشان داده شده باشند. نظیر داده های حاصل از یک دوربین ویدئوئی.
3. تابع هدف دارای مقادیر پیوسته باشد.
4. زمان کافی برای یادگیری وجود داشته باشد. این روش در مقایسه با روشهای دیگر نظیر درخت تصمیم نیاز به زمان بیشتری برای یادگیری دارد.
5. نیازی به تعبیر تابع هدف نباشد. زیرا به سختی میتوان اوزان یادگرفته شده توسط شبکه را تعبیر نمود.
پرسپترون
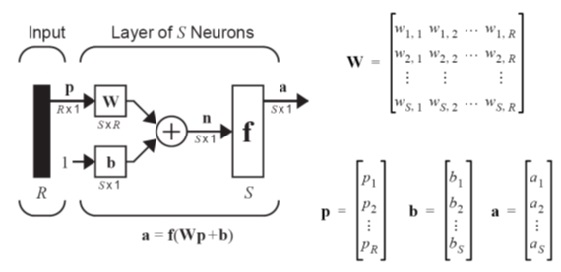
نوعی از شبکه عصبی برمبنای یک واحد محاسباتی به نام پرسپترون ساخته میشود. یک پرسپترون برداری از ورودیهای با مقادیر حقیقی را گرفته و یک ترکیب خطی از این ورودیها را محاسبه میکند. اگر حاصل از یک مقدار آستانه بیشتر بود خروجی پرسپترون برابر با 1 و در غیر اینصورت معادل -1 خواهد بود.
آموزش پرسپترون
چگونه وزنهای یک پرسپترون واحد را یاد بگیریم به نحوی که پرسپترون برای مثالهای آموزشی مقادیر صحیح را ایجاد نماید؟
دو راه مختلف : 1) قانون پرسپترون 2) قانون دلتا
الگوریتم یادگیری پرسپترون
- مقادیریتصادفی به وزنها نسبت میدهیم
- پریسپترونرا به تک تکمثالهای آموزشی اعمال میکنیم. اگر مثالغلط ارزیابی شود مقادیر وزنهای پرسپترون را تصحیح میکنیم.
- آیاتمامیمثالهای آموزشی درست ارزیابی میشوند:
- بله => پایان الگوریتم
- خیر => به مرحله 2 برمیگردیم
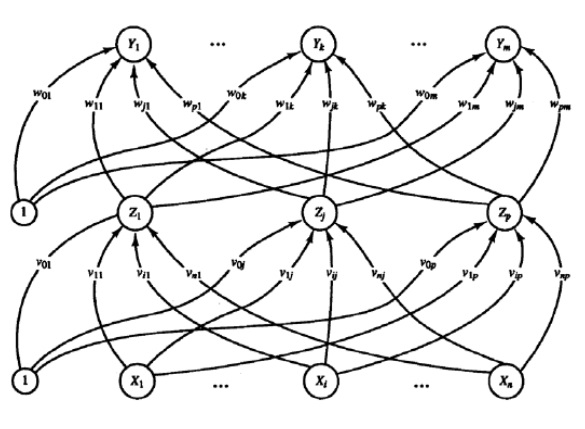 در شكل فوق يك شبكه پرسپترون با يك لايه پنهان نشان داده شده است.
در شكل فوق يك شبكه پرسپترون با يك لايه پنهان نشان داده شده است.
الگوریتم gradient descent
با توجه به نحوه تعریف E سطح خطا بصورت یک سهمی خواهد بود. ما بدنبال وزنهائی هستیم که حداقل خطا را داشته باشند. الگوریتم gradient descent در فضای وزنها بدنبال برداری میگردد که خطا را حداقل کند. این الگوریتم از یک مقدار دلبخواه برای بردار وزن شروع کرده و در هر مرحله وزنها را طوری تغییر میدهد که در جهت شیب کاهشی منحنی فوق خطا کاهش داده شود.
ایده اصلی: گرادیان همواره در جهت افزایش شیب E عمل میکند.
گرادیان E نسبت به بردار وزن w بصورت زیر تعریف میشود:
E (W) = [ E’/w0, E’/w1, …, E’/wn]
که در آن E (W) یک بردارو ’E مشتق جزئی نسبت به هر وزن میباشد.
مشکلات روش gradient descent
- ممکن است همگرا شدن به یک مقدار مینیمم زمان زیادی لازم داشته باشد.
- اگر در سطح خطاچندین مینیمم محلی وجود داشته باشد تضمینی وجود ندارد که الگوریتم مینیمم مطلق را پیدا بکند.
در ضمن این روش وقتی قابل استفاده است که:
- فضای فرضیه دارای فرضیه های پارامتریک پیوسته باشد.
- رابطه خطا قابل مشتق گیری باشد
تقریب افزایشی gradient descent
میتوان بجای تغییر وزنها پس از مشاهده همه مثالها، آنها را بازا هر مثال مشاهده شده تغییر داد. در این حالت وزنها بصورت افزایشی incremental تغییر میکنند. این روش را stochastic gradient descent نیز مینامند.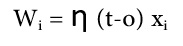
در بعضی موارد تغییر افزایشی وزنها میتواند از بروز مینیمم محلی جلوگیری کند. روش استاندارد نیاز به محاسبات بیشتری دارد درعوض میتواند طول step بزرگتری هم داشته باشد.
الگوریتم Back propagation
برای یادگیری وزن های یک شبکه چند لایه از روش Back Propagation استفاده میشود. در این روش با استفاده از gradient descent سعی میشود تا مربع خطای بین خروجی های شبکه و تابع هدف مینیمم شود. خطا بصورت زیر تعریف میشود:

منظور از outputs خروجیهای مجموعه واحد های لایه خروجی و tkd و okd مقدار هدف و خروجی متناظر با k امین واحد خروجی و مثال آموزشی d است.
فضای فرضیه مورد جستجو در این روش عبارت است از فضای بزرگی که توسط همه مقادیر ممکن برای وزنها تعریف میشود. روش gradient descent سعی میکند تا با مینیمم کردن خطا به فرضیه مناسبی دست پیدا کند. اما تضمینی برای اینکه این الگوریتم به مینیمم مطلق برسد وجود ندارد.
برخی زمينه های شبكه های عصبی
- شناسايی الگوها (Pattern recognition): شامل تشخيص چهره، اثر انگشت، تشخيص نوع صدا و نوع صحبت كردن، دستخط و...
بهعنوان مثال از اين سازوكار در بانكها در مقايسهی امضای شخص مراجعه كننده برای دريافت وجه از يك حساب و امضايی كه در پروندهی حساب ثبت شدهاست استفاده میشود. اين يكي از نخستين كاربردهای فراگير تراشههای شبكههای عصبی است. - پزشكی(Medicine): در تجزيه وتحليل وتشخيص علايم دستگاه ضرباننگار قلب (الكتروكارديوگراف)، ونيز شبكهی آموزشديدهای كه میتواند بيماری را تشخيص دهد و حتا دارو نيز تجويز كند.
- كاربردهای تجاری: انجام هرگونه تصميمگيری كه در دنيای تجارت به سهولت انجام پذير نيست، مثلاً: تصميمگيریهايی كه نياز به اطلاعات وسيعي در محدودهی هدف مورد نظر دارند. مثلاً در تلاش برای پيشبيني نوسانات سهام از روی اطلاعات قبلی در بورس از شبكهها بهوفور استفاده میشود.
- هوش مصنوعی: بسياري از كارشناسان هوش مصنوعی معتقدند شبكههای عصبی مصنوعی بهترين وشايد تنها اميد طراحی يك ماشين هوشمند هستند.
- فشردهكردن اطلاعات تصويری براي كاهش حجم اطلاعات
- حذف (Noise) در خطوط مخابراتی
- سيستمهاي نظامي: 1) شامل رديابي مينهاي زيردريايي، 2) حذف صداهاي ناهنجار در سيستمهاي رديابی رادارها و... 3)ساخت و بهرهبرداری سازههای ساختمانی: به دليل سرعت زياد شبكههای عصبی در پردازش و تحليل دادهها زمان مورد نياز براي كشف سازهی بهينه كاهش میيابد.
- بازاريابی: شبكهها برای فروش بيشتر و گزيدهتر در تبليغات اينترنتی استفاده میشوند.
- ديدهبانی و بررسی (In Monitoring) : بهعنوان مثال با بررسی ترازهاي صوتی كه از فضاپيماها مخابره میشود خطرهای پيش روی فضاپيما پيشبينی می شود. اين روش در ريلها براي بررسی صداهای توليد شده از موتورهای ديزلی نيز آزموده شده است.
از دیگر کاربرد های شبکه های عصبی می توان به سامانههای آنالیز ریسک، کنترل هواپیما بدون خلبان، آنالیز کیفیت جوشکاری، آنالیز کیفیت کامپیوتر، آزمایش اتاق اورژانس، اکتشاف روغن و گاز، سامانههای تشخیص ترمز کامیون، تخمین ریسک وام، شناسایی طیفی، تشخیص دارو، فرآیندهای کنترل صنعتی، مدیریت خطا، تشخیص صدا، تشخیص هپاتیت، بازیابی اطلاعات راه دور، شناسایی مینهای زیردریایی، تشخیص اشیاء سه بعدی و دست نوشتهها و چهره و ... در کل میتوان کاربردهای شبکههای عصبی را به صورت زیر دسته بندی کرد: تناظر (شبکه الگوهای مغشوش وبه هم ریخته را بازشناسی میکند)، خوشه یابی، دسته بندی، شناسایی، بازسازی الگو، تعمیم دهی (به دست آوردن یک پاسخ صحیح برای محرک ورودی که قبلا به شبکه آموزش داده نشده) ، بهینه سازی. امروزه شبکههای عصبی در کاربردهای مختلفی نظیر مسائل تشخیص الگو که خود شامل مسائلی مانند تشخیص خط ، شناسایی گفتار ، پردازش تصویر و مسائلی از این دست میشود و نیز مسائل دسته بندی مانند دسته بندی متون یا تصاویر، به کار میروند. در کنترل یا مدل سازی سامانههایی که ساختار داخلی ناشناخته یا بسیار پیچیدهای دارند نیز به صورت روز افزون از شبکههای عصبی مصنوعی استفاده میشود. به عنوان مثال میتوان در کنترل ورودی یک موتور از یک شبکه عصبی استفاده نمود که در این صورت شبکه عصبی خود تابع کنترل را یاد خواهد گرفت.
معایب شبکه های عصبی
با وجود برتریهایی که شبکههای عصبی بسبت به سامانههای مرسوم دارند، معایبی نیز دارند که پژوهشگران این رشته تلاش دارند که آنها را به حداقل برسانند، از جمله:
- قواعد یا دستورات مشخصی برای طراحی شبکه جهت یک کاربرد اختیاری وجود ندارد.
- در مورد مسائل مدل سازی، صرفاً نمیتوان با استفاده از شبکه عصبی به فیزیک مساله پی برد. به عبارت دیگر مرتبط ساختن پارامترها یا ساختار شبکه به پارامترهای فرآیند معمولاً غیر ممکن است.
- دقت نتایج بستگی زیادی به اندازه مجموعه آموزش دارد.
- آموزش شبکه ممکن است مشکل ویا حتی غیر ممکن باشد.
- پیش بینی عملکرد آینده شبکه (عمومیت یافتن) آن به سادگی امکان پذیر نیست.
مزیتهای شبکه های عصبی
- یادگیری انطباق پذیر: قابلیت یاد گیری نحوه انجام وظایف بر پایه اطلاعات داده شده برای تمرین و تجربههای مقدماتی.
- سازماندهی توسط خود: مزیت اصلی استفاده از شبكه عصبی در هریك از مسائل فوق قابلیت فوقالعاده شبكه عصبی در یادگیری و نیز پایداری شبكه عصبی در مقابل اغتشاشات ناچیز وروداست. به عنوان مثال اگر از روشهای عادی برای تشخیص دست خط یك انسان استفاده كنیم ممكن است در اثر كمی لرزش دست این روشها به تشخیص غلطی برسند در حالی كه یك شبكه عصبی كه به صورت مناسب آموزش داده شده است حتی در صورت چنین اغتشاشی نیز به پاسخ درست خواهد رسید. یک ANN می تواند سازماندهی یا ارائه اش را ، برای اطلا عاتیکه در طول دوره یادگیری در یافت می کند، خودش ایجاد کند.
- عملکرد بهنگام (Real time): محاسبات شبکه عصبی مصنوعی می تواند بصورت موازی انجام شود، و سختافزارهای مخصوصی طراحی و ساخته شده است که می تواند از این قابلیت استفاده کند.
- تحمل اشتباه بدون ایجاد وقفه در هنگام کدگذاری اطلاعات: خرابی جزئی یک شبکه منجر به تنزل کارایی متناظر با آن می شود اگر چه تعدادی از قابلیت های شبکه ممکن است حتی با خسارت بزرگی هم باقی بماند.
کاربرد مدلهای شبکه عصبی
در پيشبينی ورشکستگی اقتصادی شرکتهای بازار بورس
بيشتر تحقيقات در زمينه كاربرد مدلهای شبكه عصبی مصنوعی در پيشبينی ورشكستگی از جمله مدلهای «آدام و شاردا» (1990)، «كستر، سنداك و بوربيا» (1990)، «كدن» (1991)، «كوتس و فنت» (1993)، «لی، هن و كوان» (1996) به مقايسه كاربرد اين مدلها با مدلهای تحليل مميزي پرداختهاند. امّا «سالچنبرگر، سينار و لش» (1992)، «فلچر و گاس» (1993)، و «آدو» (1993) اين مدلها را با مدل «لاجيت» و «تن» (1996) نيز مدلهای مزبور را با مدل «پروبيت» مقايسه نموده است. همه مطالعات، مدلهای شبكه عصبی را در طبقهبندی نسبت به مدلهای رقيب تواناتر يافته و نشان دادهاند كه اين مدلها از قوت و انعطاف بيشتری نسبت به ساير مدلها برخوردارند.
«پرز» (1998) 24 مورد از كاربردهای تجربی شبكه عصبی مصنوعی در پيشبينی ورشكستگي شركتها را بررسی و نتايج زير را ارئه نموده است: الف) در 17 مورد از 24 تحقيقی كه در اين مطالعه بررسی شده است، از شبكه عصبی «پرسپترون چند لايه» استفاده شده است و در پنج تحقيق ديگر سعی شده است كه مقايسهای ميان پرسپترون چند لايه با ساير انواع شبكه عصبی انجام شود. در دو مطالعه هم كه يكی توسط «دل بريو و سينكا» (1993) و ديگری توسط «كيويلوتو و برجيوس» (1997) انجام شده است، از «شبكه كوهنن» كه نوعي «مدل خودسازمانده» است، استفاده شده است. مدل پرسپترون چند لايه بهعنوان مرجعی برای حل مسئله طبقهبندی محسوب میگردد و مدلهای خودسازمانده نيز که در آنها روش آموزش بدون سرپرست اجرا میشود، مسير نويدبخشی برای پيشرفت در اختيار دارند.
ب) از نقطهنظر ساختار داخلی شبكه، تعداد لايههای پنهان در شبكههای عصبی مورد استفاده در همه تحقيقات يكی است، بهجز در سه تحقيق «رگيوپسی، اسكيد و راجو» (1991)، «دیآلميدا و دومنتير» ( 1993) و «آلتمن، ماركو و ورتو» ( 1994) که از دو لايه پنهان استفاده نمودهاند. همچنين در اين مطالعات لايه خروجی مركب از يك يا دو نرون است كه نتايج اين دو يكسان است.
ج) از حيث متغيرهای استفاده شده در مدلها، همه مطالعات از اطلاعات صورتهای مالی سالانه شركتها استفاده نمودهاند. نوع نسبتهای بهكار رفته در اين مدلها نيز از مدلهای سنتی ناشی شدهاند؛ امّا هيچكدام از آنها بهجز تحقيق «كاستا و پرات» (1994) سعی نكردهاند تا سری جديدی از نسبتها را كه بهطور مشخص به توانايی مدلهای شبکه عصبی مربوط میشود استفاده نمايند. نويسندگان بين 5 تا 34 متغير را در تحقيقات استفاده نمودهاند و اكثر آنها همان نسبتهای آلتمن را برگزيدهاند.
چ) در برخی از مطالعات تنها از اطلاعات يکسال شرکتها و در برخی ديگر اطلاعات 19 سال آنها استفاده شده است؛ ولی اغلب تحقيقات از يك دوره سه تا نه ساله برای مطالعه استفاده نمودهاند.
ح) در انتخاب شركتهای نمونه از ميان 24 مطالعه، 16 تحقيق يعنی بيش از 65 درصد از آنها توجهي به صنعت خاصی نداشتهاند، با اين وجود شركتهای ورشكسته و غير ورشكسته از صنايع مشابه انتخاب شدهاند.
خ) بهجز در يک مطالعه، در ساير مطالعات اندازه شرکتهای نمونه يکسان نيست.
د) نسبت شركتهای ورشكسته و غير ورشكسته به حجم كل نمونه در مطالعات مختلف، متفاوت است. در برخی از مطالعات اين دو نسبت يكسان است، يعني نيمی از شركتهای نمونه را شركتهای ورشكسته و نيمی ديگر را شركتهای غير ورشكسته تشكيل میدهد؛ ولی در تعداد ديگری از مطالعات اين دو نسبت يكسان نيست.
ذ) از 24 تحقيق مورد بررسی، 14 مورد به مقايسه كارآيی شبكههای عصبی و مدلهای سنتی پيشبينی ورشكستگي پرداختهاند و 12 مورد شبكههای عصبی را كارآتر يافتهاند.
و در آخر:
در این قسمت توضیحاتی آموزنده در مورد شبکههای عصبی مصنوعی گذاشته شد. در آینده مطالب بیشتری را در اختیار شما قرار خواهیم داد، با آرزوی بهترینها برای شما خواننده محترم.
منابع:

دیدگاه خود را بنویسید