





مقدمه:
پردازش دادههای متنی با توجه به تولید روز افزون این دادهها در پلتفرمهای مختلف از اهمیت زیادی برخوردار است. اندازهگیری شباهت متن یکی از مهمترین عملیات در کاربردهای مختلف متنکاوی نظیر بازیابی اطلاعات، دستهبندی متن، خوشهبندی متن، خلاصهسازی متن و سیستمهای پرسش و پاسخ است. با توجه به اهمیت اندازهگیری شباهت متن، روشهای مختلفی در تحقیقات قبلی در این راستا ارائه شده است که این روشها را میتوان به صورت کلی به روشهای سنتی و روشهای مبتنی بر یادگیری عمیق دستهبندی کرد. روشهای سنتی تشابه متن در سطح کلمات عمل میکنند. یافتن شباهت بین کلمات اولین گام برای محاسبه شباهت بین جملات، پاراگرافها و اسناد است. شباهت کلمات میتواند به دو روش شباهت لغوی و معنایی باشد. کلمات به صورت لغوی مشابه هستند اگر ترتیب کاراکترهای موجود در آنها شبیه باشد. همچنین کلمات از لحاظ معنایی مشابه هستند اگر یک کارکرد مشابهی داشته باشند و در یک زمینه مشابهی استفاده گردند. به صورت کلی روشهای مبتنی بر شباهت لغوی با استفاده از الگوریتمهای مقایسه رشتهها کار میکنند. همچنین روشهای مبتنی بر شباهت معنایی بر اساس الگوریتمهای مبتنی بر پیکره متنی و مبتنی بر دانش عمل میکنند. روشهای نوین در حوزه اندازهگیری تشابه متن مبتنی بر تکنیکهای شبکه عصبی و یادگیری عمیق هستند. روشهای مبتنی بر یادگیری عمیق در ایجاد بازنمایی درستی از کلمات نتایچ موفقیت آمیزی داشتهاند. روش تعبیه کلمات کار بازنمایی کلمه را با در نظر گرفتن کلمات اطراف آن در یک پیکره متن انجام میدهند. خروجی یک روش تعبیه کلمه، یک بردار (معمولا ۳۰۰ عنصری از اعداد حقیقی) که معنی کلمه را منعکس میکند. کلماتی که دارای معانی مشابهی هستند، بردارهای نزدیکتری را دارند. بسیاری از رویکردهای جدید از بردارهای تعبیه کلمه برای اندازهگیری شباهت جملات استفاده میکنند که این رویکردها در دسته یادگیری بدون نظار طبقهبندی میشوند. تکنیکهای یادگیری عمیق شبکه مانند شبکههای عصبی بازگشتی شبکه حافظه کوتاه مد طولانی (LSTM)، در سالهای اخیر توجه زیادی را به خود جلب کردهاند. با استفاده از این روشها یک بازنمایی از جملا و متنها با در نظر گرفتن ترتیب کلمات بدست میآید. شبکههای عصبی بازگشتی توانایی پردازش وابستگی بین کلمات را دارند و بازنمایی ایجاد شده توسط آنها به اندازهگیری دقیق شباهت متون کمک میکند. در دسته دیگری از تحقیقات قبلی بازنمایی ایجاد شده توسط لایههای شبکههای عصبی بازگشتی اغلب در یک معماری شبکه عصبی سیامی مورد استفاده قرار گرفته است و نتایچ خوبی در زمینه اندازهگیری شباهت متن حاصل شده است. روشهای ارائه شده در این تحقیقات جز دسته روشهای یادگیری با نظارت هستند. شبکه عصبی سیامی یک نوع شبکه عصبی خاص است که در وظایف مربوط به اندازهگیری تشابه یا رابطه بین دو چیز قابل مقایسه (برای مثال دو تصویر) بسیار مورد استفاده قرار میگیرد. شبکههای سیامی شامل دو یا چند زیرشبکه یکسانی هستند که هر کدام از آنها دارای پیکره بندی مشابه و پارامترهای مشترکی هستند. عملکرد موفق روشهای یادگیری عمیق در پژوهشهای پیشین مورد تایید قرار گرفته است. در این تحقیق به بررسی این موضوع میپردازیم که ترکیب ویژگیهای بدست آمده از شبکه عصبی عمیق با ویژگیهای شباهت لغوی منجر به بهبود عملکرد مدل یادگیری عمیق میشود یا خیر. در این راستا یک رویکرد ترکیبی مبتنی بر شبکه عصبی سیامی در این تحقیق ارائه میشود. در رویکرد ترکیبی ارائه شده با در نظر گرفتن لایههای عمیق شامل شبکه حافظه کوتاه_مدت طولانی، شبکه پیچشی و شبکه حافظه کوتاه-مدت طولانی دو طرفه و همچنین با استفاده از دو رویکرد تعبیه کلمات، مدلهای مختلفی پیادهسازی شده و بر روی مجموعه داده N2C2 اعمال شدند. نتایچ ارزیابی مدلها با استفاده از معیار همبستگی پیرسون و میانگین مربع خطاها نشان داد که مدل ترکیبی با استفاده از شبکه پیچشی بهترین نتیجه در پیشبینی شباهت را در بین مدلها دارد. به صورت کلی مدلهای ترکیبی نتیجه بهتری نسبت به مدلهای پایه مبتنی بر شبکه عمیق دارند. همچنین مدل پیشنهادی نسبت به مدلهای ارائه شده در عملکرد بهتری دارد.
کارهای مرتبط
در این بخش ابتدا به مرور کلی تحقیقات قبلی پرداخته و سپس به توصیف روشهای یادگیری عمیق بکار گرفته شده در رویکرد پیشنهادی می پردازیم.
1. مروری بر روشهای تخمین شباهت متن مبتنی بر تکنیکهای یادگیری عمیق
روشهای نوین در حوزه اندازهگیری تشابه متن با استفاده از تکنیکهای شبکه عصبی و یادگیری عمیق ارائه شدهاند. این روشها به طور کلی به دو دسته روشهای بی نظارت و با نظارت تقسیم میشوند. روشهای بدون نظار مبتنی بر یادگیری عمیق بر اساس بازنمایی ایجاد شده توسط یک روش تعبیه کلمه عمل میکنند و با داشتن بردار هر کلمه، بردار جملات را بدست آورده و با استفاده از معیارهای شباهت نظیر معیار کسینوسی، شباهت بین دو جمله یا متن را محاسبه میکنند. در دسته روشهای با نظارت، معماریهای مختلف شبکه عصبی عمیق جهت یادگیری مدل اندازه گیری تشابه مورد استفاده قرار گرفته است که در این میان شبکههای یادگیری عمیق مانند شبکههای عصبی بازگشتی، شبکه حافظه کوتاه مدت طولانی از روشهای پرکاربرد در این زمینه محسوب میشوند. این شبکهها بردار تعبیه کلمات مربوط به دو متن را به عنوان ورودی گرفته و بازنمایی منعکسکننده معنای آن دو متن را با استفاده از شبکه عمیق بدست آورده و بر اساس آن کار پیشبینی شباهت را انجام میدهند. این تحقیقات غالبا از یک معماری شبکه عصبی سیامی استفاده کرده و عملکرد موفقی در زمینه اندازهگیری شباهت متن به دست آوردهاند. جدول 1 چندین نمونه از تحقیقات مبتنی بر یادگیری عمیق را با ارائه اطلاعاتی درباره نوآوری روش ارائه شده، رویکرد و معیارها و ابزارهای مورد استفاده و مجموعه داده انتخاب شده جهت انجام آزمایشات نشان میدهد.
2. روشهای مورد استفاده در این پژوهش
در این تحقیق از ۳ شبکه عصبی بازگشتی حافظه کوتاه_مدت طولانی، شبکه عصبی بازگشتی حافظه کوتاه_مدت طولانی دو طرفه و شبکه عصبی پیچشی استفاده میکنیم. در بخشهای زیر هرکدام از این شبکهها را به صورت مختصر توضیح میدهیم.
- شبکه کانولوشنی: شبکه عصبی پیچشی یکی از مهمترین روشهای یادگیری عمیق هستند که در آنها چندین لایه با روشی قدرتمند آموزش میبینند این روش بسیار کارآمد بوده و یکی از رایجترین روشها در کاربردهای مختلف بینایی کامپیوتر است. یک لایه پیچشی دادههای ورودی متن را دریافت کرده و با انجام عملیات کانولوشن با استفاده از کرنلهای کانولوشن ویژگیهای جدیدی از متن را استخراج میکند. هر لایه کانولوشن شامل یک کرنل (یک پنجره کوچک) است که روی دادهها حرکت کرده و از طریق انجام عملیات کانولوشنی ویژگیهای جدید را محاسبه میکند. ویژگیهای جدید قابلیت متمایزسازی بالایی نسبت به دادههای خام ورودی داشته و باعث بهبود دقت پیشبینی میشود.
- شبکه LSTM: شبکه LSTM یک نوع شبکه عصبی بازگشتی بهبود یافته است که توسط هوچریتر و اشمیت توسعه داده شده است. این شبکه برای رفع مشکل ناپدید شدن گرادیان و عدم یادگیری توالیهای طولانی در شبکههای عصبی بازگشتی معرفی شده است و توانایی به یاد سپاری اطلاعات برای بازههای زمانی بلند مدت را دارد همچنین LSTM میتواند اطلاعات وابستگیهای طولانی مدت در داده های متنی را استخراج کرده و به طور مناسب بین داده ورودی و خروجی نگاشت ایجاد کند. مطابق شکل LSTM ۱ از چهار بخش سلول حافظه C ، دروازه ورودی i ، دروازه فراموشی f ، و دروازه خروجی o تشکیل شده است. دروازه ورودی it تشخیص میدهد که از کدام مقدار ورودی باید برای بهبود حافظه استفاده شود. اینکه تا چه حدی اطلاعات حافظه فعلی فراموش شود توسط دروازه فراموشی، ft تعیین میشود. دروازه خروجی ot اطلاعات خروجی واحد LSTM را تنظیم میکند.
جدول ا: بررسى روشهاى شباهت متن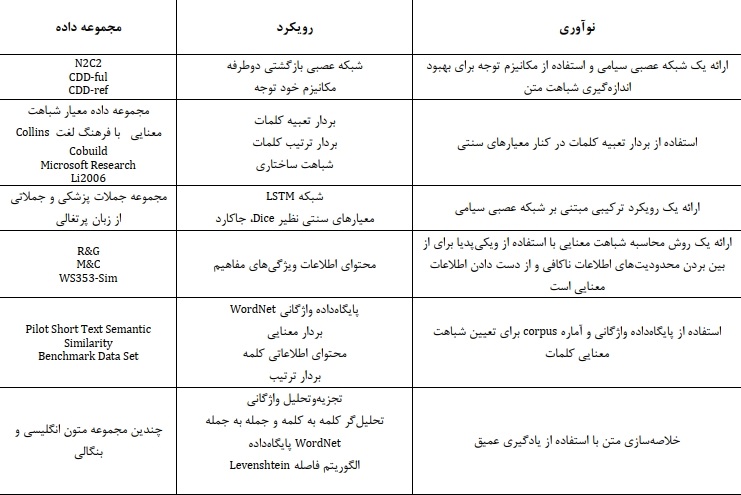
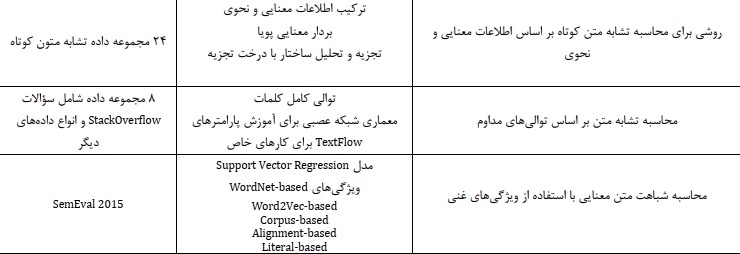
شكل ١: ساختاريك واحد شبكه حافظه كوتاه_مدت طولانى
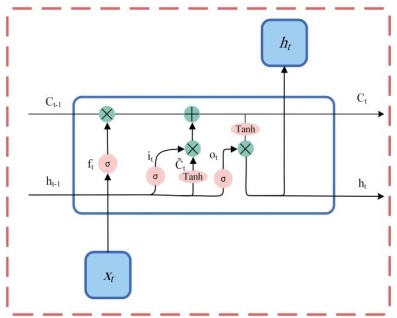
- LSTM دوطرفه: با توصيف جزئيات مربوط به هر واحد از LSTM در بخش قبلى در اين بخش به توصيف LSTM دوطرفه مپردازيم. اين مدل از دو LSTM يكطرفه جداگانه تشكيل شده است كه در مسائل مدلسازى ترتيبى عملكرد مناسبى از خود نشان داده است و همچنين يكى از مدلهاى پركاربرد در طبقهبندى متون محسوب میشود. شكل ٢ معمارى يك شبكه LSTM دو طرفه را نشان میدهد. همانطور كه Forward LSTM، در شكل مشاهده میشود با داشتن يك جمله به عنوان ورودى محاسبات رو به جلو را انجام میدهد، يعنى از ابتداى جمله شروع مىكند و محاسبات را انجام داده و خروجى را در هر نقطه زمانى (به ازاى هر كلمه)، بر اساس اطلاعات كلمات مجاور بدست میآورد. همچنين Backward LSTM از انتهاى يك جمله شروع كرده و در جهت عكس محاسبات را انجام میدهد و در نهايت بازنمايى حاصل از هر دو LSTM تركيب میشود.
شکل ۲: معماری یک شبکه LSTM دوطرفه
3. روش پیشنهادی
در بخش ۲ خلاصهای از رویکردهای مختلف برای یافتن شباهت بین متون بیان شد. استفاده از شبکههای عصبی عمیق جهت آموزش مدلهای اندازهگیری تشابه یکی از رویکردهای نوین در سالهای اخیر است. در این مطالعه به دنبال ارائه رویکردی برای بهبود دقت مدلهای یادگیری عمیق در اندازهگیری تشابه متون هستیم. بدین ترتیب با بهکارگیری لایههای مختلف یادگیری عمیق نظیر شبکه پیچشی، حافظه کوتاه مدت طولانی و همچنین حافظه کوتاه مدت طولانی دوطرفه و با گنجاندن ویژگیهای شباهت لغوی نظیر شباهت کسینوسی، یک روش شبکه عصبی سیامی ترکیبی برای محاسبه شباهت بین متن ارائه میکنیم. در این بخش ابتدا به توصیف مسئله شباهت متن میپردازیم سپس رویکرد پیشنهادی تحقیق را تشریح میکنیم.
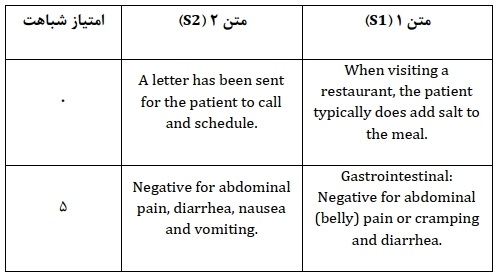
- مسئله شباهت متن: در این بخش مسشله شباهت متن را با در نظر گرفتن شکل زیر توضیح میدهیم. ورودی الگوریتم پیشبینی شباهت، دو متن S2,S1 است. بهازای دو متن ورودی یک امتیاز شباهت بین • تا ۵ وجود دارد که امتیاز • نشان دهنده عدم تشابه و امتیاز ۵ بیانگر کاملاً مشابه است (جدول ۲) هدف الگوریتم، پیشبینی شباهت دو متن بر اساس مدل آموزش دیده است.
جدول ۲: مثالهایی از جفت جملات و امتیاز شباهت آنها: امتیاز صفر نشان دهنده عدم شباهت بین دو جمله و امتیاز ۵ نشاندهنده شباهت کامل بین دو جمله است.
- رویکرد پیشنهادی: شکل ۳ ساختار کلی رویکرد پیشنهادی این تحقیق برای محاسبه شباهت بین متن را نشان میدهد. همانطور که اشاره شد، رویکرد پیشنهادی عبارت است از یک معماری شبکه عصبی سیامی که شامل ویژگیهای شباهت رایچ است. اجزای اصلی رویکرد پیشنهادی عبارتند از: 1) لایه ورودی 2) لایه تعبیه کلمات 3) لایه اصلی 4) لایه تماما متصل 5) لایه خروجی. ابتدا عملیات پیش پردازش روی جملات انجام میگیرد. این عملیات شامل جداسازی کلمات و حذف کلمات توقف است. جملات پیش پردازش شده در ادامه عملیات وارد لایه تعبیه کلمات میشوند که به هر کلمه یک بردار حقیقی تعبیه کلمات نسبت داده میشود. برای بدست آوردن بردار تعبیه هر کلمه علاوه بر استفاده از لایه تعبیه کتابخانه کراس، از مدلهای از پیش آموزش دیده در این حوزه نیز استفاده میشود. در ادامه به ازای هر جمله بردارهای کلمات آن ادغام شده و بردار مربوط به هر جمله تشکیل میشود که این بردارها وارد لایههای شبکه عصبی عمیق میشوند. همانطور که در شکل ۳ مشاهده میشود، در این تحقیق از سه لایه حافظه کوتاه_مدت طولانی، حافظه کوتاه_مدت طولانی دوطرفه و شبکه پیچشی استفاده میکنیم. وظیفه این لایه ایجاد یک بازنمایی جدید از هر یک از جملات ورودی است طوری که بتواند معنای موجود در جمله را بیان کند. به جهت اینکه از معماری شبکه عصبی سیامی استفاده شده است، متناظر با هر زیرشبکه در شبکه سیامی، یک نوع لایه استفاده شده است (لایه A). همچنین در مدل پیشنهادی سه ویژگی شباهت لغوی رایچ شامل معیار شباهت کسینوسی، جاکارد، دایس جهت بهبود مدل محاسبه شده و با ادغام با بردارهای خروجی مسطح شده لایههای اصلی وارد یک لایه تماما متصل میشود. در ادامه یک لایه حذف تصادفی در مدل قرار داده میشود که وظیفه آن جلوگیری از پیش پرازش مدل است. خروجی لایه تماما متصل پس از عبور از لایه حذف تصادفی وارد لایه خروجی میشود که کار پیشبینی شباهت بین دو جمله را انجام میدهد.
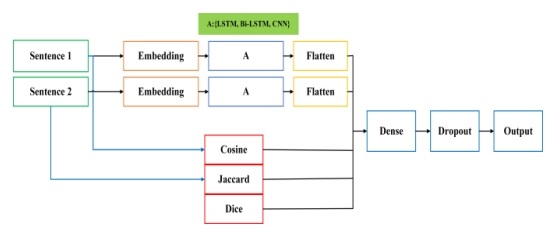
شکل ۳: رویکرد پیشنهادی برای پیش بینی تشابه جملات
ویژگیهای لغوی مطابق با فرمول (1) محاسبه میشوند. در این فرمول، S1 و S2 به ترتیب مجموعه کلمات جمله ا و جمله ۲ در شکل ۳ میباشند.

4. آزمایشهای عملی و نتایچ
در این بخش ابتدا به توصیف مجموعه دادههای مورد استفاده جهت انجام آزمایشها پرداخته سپس معیارهای اندازهگیری عملکرد مدلها و تنظیمات مدلها و نتایج را بیان میکنیم. در این مطالعه از کتابخانه Keras جهت پیادهسازی مدلها استفاده میکنیم.
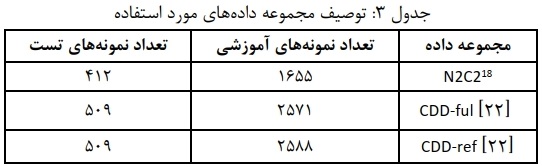
- مجموعه دادهها: در این مطالعه، از سه مجموعه داده استاندارد پزشکی که هر کدام شامل مجموعهای از جفت جملات با نمرات شباهت/ مرتبط بودن است، استفاده میکنیم. توصیف مجموعه دادهها در جدول ۳ بیان شده است.
- معیارهای اندازهگیری:
در این تحقیق، دقت مدلها با استفاده از معیارهای همبستگی پیرسون و معیار MSE محاسبه میشود. با در نظر گرفتن n جفت جمله (P= (P1,P2,...,Pn و مجموعههای ![]() و
و![]() ,...,
,...,![]() ,
,![]() =
=![]() به ترتیب به عنوان امتیازات شباهت واقعی و پیشبینی شده مجموعه P، معیار همبستگی پیرسون با استفاده از رابطه (2) محاسبه میشود:
به ترتیب به عنوان امتیازات شباهت واقعی و پیشبینی شده مجموعه P، معیار همبستگی پیرسون با استفاده از رابطه (2) محاسبه میشود:
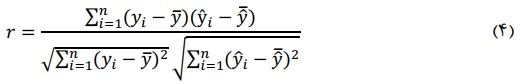
همچنین معیار میانگین مربع خطاها با رابطه (۳) محاسبه میشود.

که در رابطههای ( ۴ ) و ( ,yi (۵, ![]() به ترتیب نشاندهنده امتیاز شباهت واقعی و پیشبینی شده جفت جمله pi است. در رابطه (۲)
به ترتیب نشاندهنده امتیاز شباهت واقعی و پیشبینی شده جفت جمله pi است. در رابطه (۲) ![]() و
و ![]() (y که توان و خط بالای آن« دارد) به ترتیب مقادیر میانگین مجموعه را نشان میدهند.
(y که توان و خط بالای آن« دارد) به ترتیب مقادیر میانگین مجموعه را نشان میدهند.
- تنظیمات آزمایش: تنظیم هایپرپارامترها نقش مهمی در عملکرد مدلهای یادگیری عمیق دارد. پارامترها و هایپرپارامترهای مورد استفاده در هر لایه در جدول ۴ توصیف شده است.
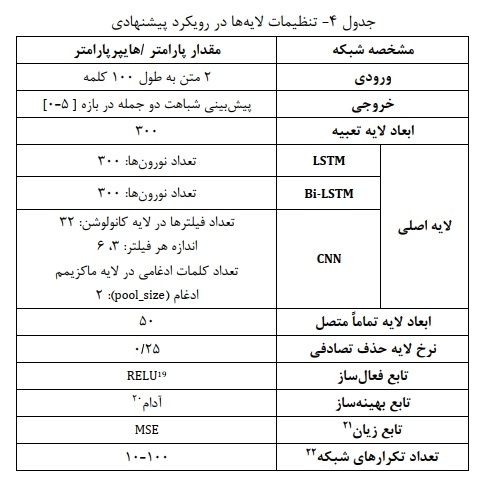
- نتایج: در این بخش با در نظر گرفتن رویکرد پیشنهادی (شکل ۳) و بکارگیری دو لایه تعبیه شامل لایه تعبیه کتابخانه Keras و لایه تعبیه از پیش آموزش دیده Wiki-PubMed-PMC23 و همچنین استفاده از انواع مختلف لایههای شبکه عصبی (بلوک A )، مدلهای مختلفی را روی سه مجموعه داده مورد آزمایش قرار دادیم. در جدولهای نتایج عملکرد مدلها، لایه تعبیه کراس با عدد ا و لایه تعبیه از پیش آموزش دیده Wiki-PubMed-PMC با عدد ۲ کدگذاری شده است.
- نتایچ مدلها روی مجموعه داده N2C2:
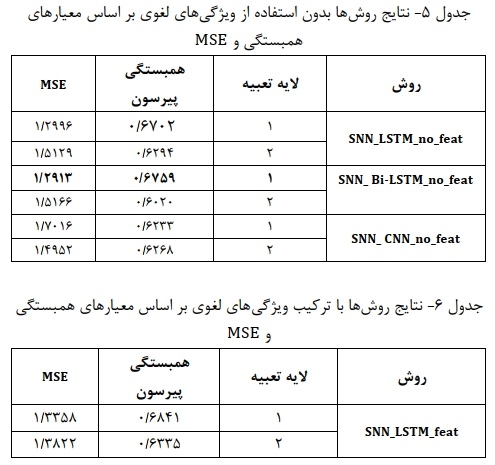
نتایج به کارگیری مدلها روی مجموعه داده N2C2 در جدولهای 5 و 6 آورده شده است. جدول 5 نتایچ روشهای یادگیری عمیق بدون استفاده از ویژگیهای لغوی شامل Cosine ,Jaccard ,Dice را نشان میدهد. همچنین جدول 6 نتایچ روشهای ترکیبی شامل ویژگهای لغوی اشاره شده را نمایش میدهد. مطابق جدول 5 از بین روشهای استفاده شده، مدل SNN_Bi-LSTM_no_feat با لایه MSE بالاترین مقدار همبستگی (۰/۶۷۵۹) و پایینترین خطا ،Keras تعبیه (۱/۲۹۱۳) را در پیشبینی شباهت جملا به دست اورده است. همچنین مدل SNN_LSTM_no_feat با لایه تعبیه Keras نتایچ نزدیکتری نسبت به مدل برتر بدست آورده است. بررسی نتایچ مدلها در جدول بیانگر آن است که استفاده از مدل از پیش آموزش دیده در لایه تعبیه باعث بهبود در نتایچ هیچ یک از مدلها نشده است.
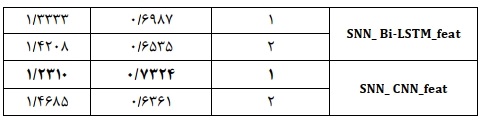
در جدول 6 نتایچ مربوط به مدلهای ترکیبی نمایش داده شده است. همانطور که مشخص است مدل شبکه عصبی سیامی ترکیبی مبتنی بر شبکه پیچشی و ویژگیهای لغوی به همراه لایه تعبیه کراس ( SNN_CNN_feat ) بالاترین مقدار همبستگی ( ۰/۷۳۲۴ ) و کمترین مقدار خطای MSE ( ۱/۲۳۱۰ ) را به دست آورده است. پس از این مدل، به ترتیب مدلهای مبتنی بر شبکه حافظه کوتاه_مدت طولانی دوطرفه ( SNN_Bi-LSTM_feat ) و شبکه حافظه کوتاه_مدت طولانی ( SNN_LSTM_feat ) بهترین نتایچ را به دست آوردهاند. مقایسه نتایچ جدولهای 5 و 6 نشان میدهد که افزودن ویژگیهای لغوی باعث بهبود نتایچ هر سه مدل شده است و میزان بهبود برای مدل مبتنی بر شبکه عصبی پیچشی بیشتر از سایر مدلها است. میزان بهبود برای این مدل بر مبنای معیار همبستگی برابر با ۰.۱۰۹۱ و همچنین میزان کاهش خطای این مدل در مقایسه با مدل غیر ترکیبی متناظر آن، برابر با ۴۷۰۶ .• است.
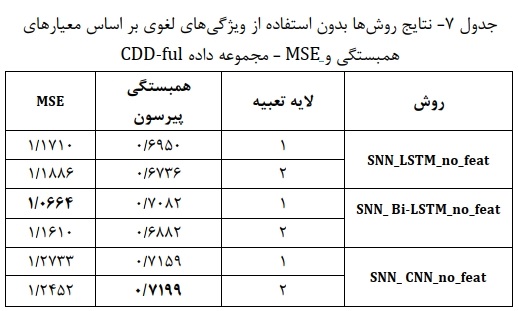
- نتایج مجموعه داده CDD-ful: در این بخش نتایچ مربوط به مدلهای استفاده شده روی مجموعه داده CDD-ful را توصیف میکنیم.جدولهای 7 و 8 به ترتیب نتایچ مدلها را برای حالت پایه و ترکیبی نمایش میدهد. در معیار همبستگی پیرسون نتایچ روشهای پایه نشان از برتری روش شبکه پیچشی با مدل تعبیه کلمات PubMed-PMC دارد. همچنین در معیار MSE روش LSTM دوطرفه با لایه تعبیه کراس بهترین عملکرد را دارد. نتایچ مدلهای ترکیبی توصیف شده در جدول ۸ نشان میدهد که در مدلهای ترکیبی که در هر دو معیار همبستگی پیرسون و خطای MSE، روش شبکه پیچشی با لایه تعبیه Keras عملکرد بهتری نسبت به سایر مدلها داشته است. همچنین روش LSTM دوطرفه عملکرد نزدیکتری نسبت به مدل برتراز خود نشان میدهد. مطابق جدول ۸ از بین روشهای استفاده شده، مدل SNN_CNN_Feat با لایه MSE تعبیه کراس، بالاترین مقدار همبستگی (۰/۷۳۴۲) و پایینترین خطا (۰/۹۸۴۵) را در پیشبینی شباهت جملات به دست آورده است. پس از این مدل، مدل ترکیبی مبتنی بر شبکه حافظه کوتاه مدت طولانی دوطرفه SNN_Bi-LSTM_Feat با لایه تعبیه کراس بهترین نتیجه را به دست میآورد.
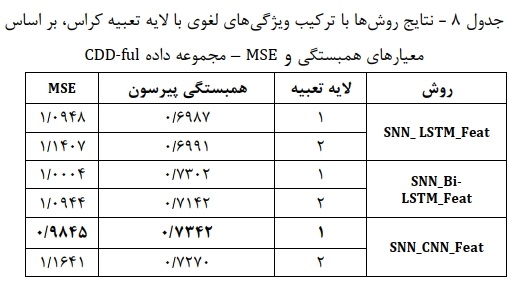
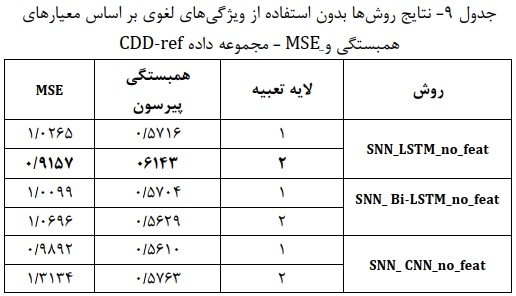
- نتایج مجموعه داده CDD-ref: برای این مجموعه داده نتایچ مدلهای پایه و ترکیبی به ترتیب در جدولهای ۹ و ۱۰ نمایش داده شده است. در بین روشهای پایه از نظر معیار همبستگی پیرسون، روش LSTM با مدل تعبیه کلمات Wiki- PubMed-PMC بهترین عملکرد را دارد. همچنین این روش در معیار MSE بهتر از سایر مدلها عمل میکند.
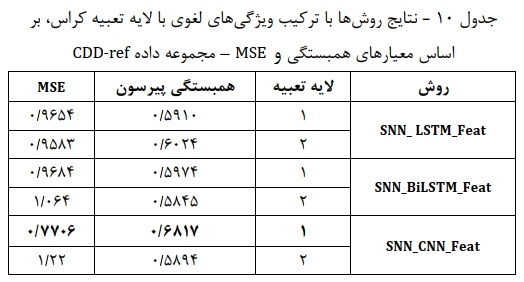
همچنین نتایچ حاصل از مدلهای ترکیبی در جدول 10 حاکی از آن است که در هر دو معیار همبستگی پیرسون و خطای MSE روش شبکه پیچشی با لایه تعبیه Keras بهترین عملکرد را کسب میکند.
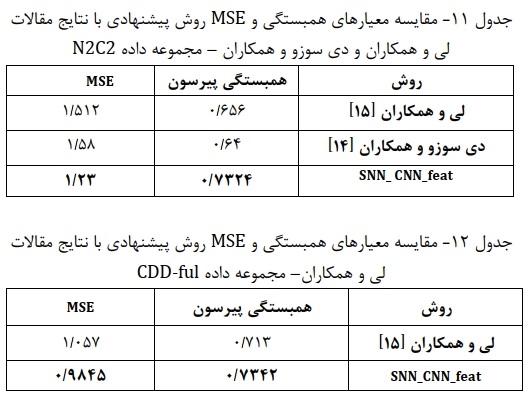
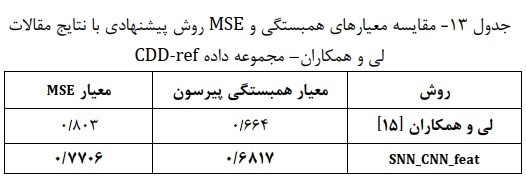
- مقایسه نتایج مدلها با روشهای ارائه شده در تحقیقات کنونی: برای بررسی بیشتر عملکرد مدلها روی سه مجموعه داده مورد استفاده، در جدولهای ۱۲،۱۱ و ۱۳ نتایچ مدل برتر بدست آمده در این مطالعه را با نتایچ ارائه شده در مقالات لی و همکاران و دی سوزو و همکاران بر اساس معیارهای همبستگی پیرسون و خطای MSE مقایسه میکنیم. با بررسی نتایچ موجود در جدول ۱۱ به این نتیجه میرسیم که مدل بدست آمده در این مطالعه دارای عملکرد بهتری از نظر معیارهای همبستگی پیرسون و MSE میباشد. مدل بدست آمده از روش پیشنهادی در این تحقیق بر مبنای معیار همبستگی پیرسون با اختلاف ۰.۰۹۲۴ و ۰.۰۷۵۴ به ترتیب قویتر از مدل پیشنهادی دی سوزو و همکاران و همچنین مدل ارائه شده توسط لی و همکاران است. همچنین با درنظر گرفتن معیار MSE، مدل بدست آمده در این تحقیق بهتر از روشهای ارائه شده در لی و همکاران و دی سوزو و همکاران بوده و به ترتیب با اختلاق ۰.۳۵ و ۰/۲۸۲۰ نسبت به این مدلها پیشی گرفته است. همچنین مطابق جدول ۱۲ ، روی مجموعه داده CDD-ful، مدل برتر بدست آمده توسط روش پیشنهادی ( SNN_CNN_feat ) عملکرد بهتری نسبت به روش ارائه شده در لی و همکاران از خود نشان میدهد. به طور خاص در معیار همبستگی پیرسون با اختلاق ۰/۰۲۰۹ بهتراز روش لی و همکاران عمل میکند. همچنین در معیار MSE با اختلاف ۰/۰۷۲۵ نسبت به آن روش پیشی گرفته است. علاوه بر این، براساس نتایج جدول 13 در مجموعه داده CDD-ref نیز مدل حاصل از روش پیشنهادی این مطالعه، عملکرد بهتری نسبت به مدل پیشنهادی در لی و همکاران از خود نشان میدهد.
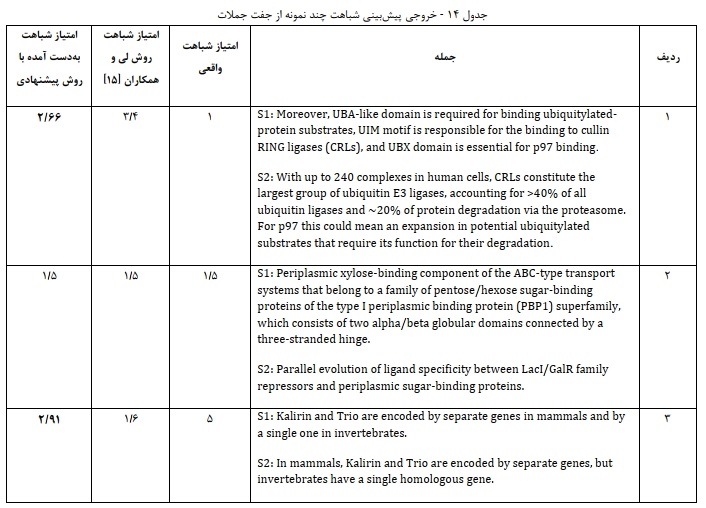
- نمایش چند نمونه از نتایج پیش بینی شباهت با استفادهد از مدل پیشنهادی: در جدول 14 برای بررسی بیشتر دقت مدلها خروجی پیشبینی شباهت چند نمونه از جفت جملات نمایش داده شده است. همانطور که در این جدول قابل مشاهده است، مدل پیشنهادی در این مطالعه امتیاز شباهت نزدیکتری به امتیاز شباهت واقعی در مقایسه با روش پیشنهادی لی و همکاران به دست میآورد.
نتیجه گیری
اندازهگیری دقیق شباهت بین متون اهمیت زیادی در بسیاری از کاربردهای مرتبط با متن نظیر سیستمهای پرسش و پاسخ، خلاصه سازی متون، بازیابی اطلاعات دارد. در این تحقیق یک رویکرد ترکیبی مبتنی بر شبکه عصبی سیامی و ویژگیهای شباهت لغوی ارائه شد. شبکه سیامی پیشنهادی شامل دو زیر شبکه یکسان است که اجزای اصلی هر کدام از آنها به صورت کلی شامل یک لایه تعبیه کلمات، شبکه عصبی عمیق است. با در نظر گرفتن سه نوع شبکه عصبی عمیق شامل: LSTM، CNN، Bi-LSYM و همچنین دو لایه تعبه کلمات به همراه ویژگیهای شباهت لغوی، چندین مدل پیاده سازی شد. نتیج آزمایشات بر سه مجموعه داده نشان داد که تمامی مدلهای ترکیبی نسبت به مدلهای پایه خود دارای مقدار همبستگی پیرسون بالاتر و خطای MSE کمتری هستند. همچنین مدل شبکه سیامی ترکیبی مبتنی بر شبکه عمیق پیچشی عملکرد بهتری نسبت به سایر مدلها بر مبنای هر دو معیار مقدار همبستگی پیرسون و خطای MSE از خود نشان داد. مقایسه نتایج این تحقیق با نتایج مقالات دیگر نشان می دهد که مدل به دست آمده در این تحقیق دارای عملکرد بهتر از نظر معیارهای همبستگی پیرسون و MSE در تخمین شباهت جملات میباشد. استفاده از روش تعبیه کلمات BERT راه مکانیزم خود توجه از کارهای آتی این پژوهش می باشد.
و در آخر:
در این قسمت توضیحاتی آموزنده در مورد پیشبینی شباهت متن با استفاده از یک شبکه عصبی سیامی مبتنی بر شبکه عمیق و ویژگیهای شباهت لغوی گذاشته شد. در آینده مطالب بیشتری را در اختیار شما قرار خواهیم داد، با آرزوی بهترینها برای شما خواننده محترم.
منابع:
فریبا خلج، حسین عباسی مهر، "پیشبینی شباهت متن با استفاده از یک شبکه عصبی سیامی مبتنی بر شبکه عمیق و ویژگیهای شباهت لغوی".

دیدگاه خود را بنویسید