





مقدمه:
امروزه گردشگری، جذب توریسم و معرفی جاذبههای دیدنی یک کشور یکی از مهمترین منابع درآمدی میباشد، کشورهای جهان برای جذب توریسم از روشهای مختلف تبلیغاتی، برنامههای تشویقی و امکانات جدید معرفی تحت وب کارهای فراوانی انجام میدهند، در این راستا کشور ایران با سابقه تاریخی و مکانهای توریستی فراوان یکی از پر جاذبهترین نقاط گردشگری میباشد که باید از روشهای مختلفی برای این امر تلاش کرد که یکی از مهمترین روشهای استفاده، معرفی و کسب درآمد از فضای مجازی تحت وب میباشد، از این رو بهرهگیری از امکانات تحت وب با استفاده از سیستمهای پیشنهاد دهنده و تصاویر دارای برچسب جغرافیایی نقش بسزایی در معرفی جاذبههای گردشگری دارد، در این تحقیق با استفاده از سیستمهای پیشنهاد دهنده و بهرهگیری از فیلترینگ مشارکت محور که یکی از مناسبترین روشها برای معرفی مکانهای گردشگری نسبت به علایق کاربر برای تعیین مسیر حرکت، زمان حرکت و فاصله بین مبدا تا مقصد و اطلاعا مسیرها میباشد که به صورت کاملاً گرافیکی به گردشگران ارائه میشود. این روش یک راهکار مناسب برای جذب گردشگر و برنامهریزی سفر در صده تکنولوژی محسوب میگردد. هر روشی فواید خاصی خود را دارد و محقق بر اساس اطلاعات موجود و تحقیقات که در حوزه موضوع انتخابی انجام میدهد. افزایش کارایی سیستم تلاش میکند، در این تحقیق نیز فوایدی میتوان ذکر نمود که موجب ارتقاء روشها پیشین میگردد:
- استفاده از فیلترینگ CF موجب افزایش کارایی سیستم میشود.
- ورود اطلاعات در پایگاه داده موجب حذف شروع سرد در فیلترینگ CF می گردد.
- امتیاز دهی برای تصاویر (سیستم پاداش و جریمه) موجب حذف مکان های جعلی کاربران می گردد.
- بهره گیری از سیستم تحت وب محدودیت های جغرافیایی را از بین می برد.
مکانیزمها و الگوریتمهای مختلفی در سیستم مشارکت محور وجود دارد، اما روش کلی کار بدین صورت است که سیستمها باید از علایق و ترجیحات کاربران آگاهی داشته باشند تا بتوانند پیشنهاداتی مناسب و شخصی سازی شده در اختیار کاربران قرار دهند. کاربران در این سیستمها مناطق گردشگری مختلف را ارزیابی و رتبهبندی میکنند و شاخصهای کمی به آنها نسبت میدهند. بر این اساس پایگاه داده جامعی پدید میآید و در انتها سیستم قادر است با تکیه بر دادههای موجود در اين پايگاه داده پيشنهادات لازم پيرامون اقلام جديد را به كاربران ارائه دهد. در حقيقت در اين روش از ميزان تشابه علاقهمندىهاى كاربران استفاده مىشود و اصطلاحاً افرادى كه داراى علاقهمندىهاى مشترك هستند در يك همسایگی قرار مىگيرند. الگورتيمهاى موجود در سيستمهاى CF به دو دسته كلى تقسيم مىشوند: الگوريتمهاى مبتنى بر حافظه كه پيشنهادات را بر اساس نزديكترين همسايگان ارائه مىكنند و الگوريتمهاى مبتنى بر مدلسازى كه پيشنهادات را بر اساس مدلى كه طبق پيشنهادات كاربران درست شده است، ارائه مىدهد. سيستمهاى CF با چالشهاى مختلفى رو به رو هستند. از جمله بارزترين آنها مسئله شروع سرد يا تخمينزن-اول است. اين پديده براى اقلامى كه به تازگى به سيستم افزوده شدهاند رخ مىدهد. چالش كليدى بعدى بحث پراكنندكى است. در بسيارى از موارد تعداد ارزيابىها و اظهار نظرهاى كاربران خيلى كمتر از تعداد اقلام موجود در سيستم مىباشد. در نتيجه سيستم نمىتواند براى تمامى اقلام موجود پيشهادات شايسته ارائه دهد. از جمله ديگر چالشهاى فنى پيش رو بحث مقياسپذيرى است، الگوريتمهاى مرسوم در سيستمهاى CF وقتى با پايگاههای داده بزرگ سروكار داشته باشند، به كندى عمل مىكنند، در نتيجه نمىتوان از آنها در كاربردهاى تحت وب كه نياز به پاسخگويى سريع دارند بهره برد.
انواع مختلف دستهبندى CF
CF را مىتوان به طور كلى از دو ديدگاه دستهبندى كرد. ديدگاه اول مربوط به استخراج اطلاعات و ديدگاه دوم مربوط به جمعآورى دادهها مىباشد. در ديدگاه استخراج دادهها نحوه ارائه پيشنهادات به كاربران بررسى مىشود كه از دو نوع الگوريتم متفاوت بسته به شرايط استفاده مىشود. نوع أول الگوريتمهاى مبتنى بر حافظه هستند كه اين الگوريتمها براى ارائه پيشنهادات از ماتريس كامل رتبهبندى استفاده مىكنند. نوع دوم الگوريتم هاى مبتنى بر مدل هستند كه اين الگوريتمها براى ارائه پيشنهادات از ماتريس رتبهبندى براى ايجاد يك مدل استفاده مىكنند و سپس با استفاده از اين مدل پيشنهادات را ارائه مىدهند. الگوريتمهاى مبتنى بر حافظه نسبت به الگوريتمهاى مبتنى بر مدل نتيجه بهتر و دقيقترى مىدهند و هنگامى كه ماتريس ارزيابى مرتبا تغيير مىكند مناسبتر مىباشند. از جهت ديگر اين الگوريتمها زمان محاسباتى زيادى نياز دارند كه اين امر باعث مىشود تا در پايگاه دادههاى بزرگ از الگوريتمهاى تقريبى مبتنى بر مدل استفاده شود. در ديدگاه جمع آورى دادهها نحوه جمع آورى اطلاعات از كاربران بررسى مىشود كه به طور كلى دادهها به دو دسته تقسيم مىشوند. دسته اول دادههاى استخراج شده از رفتار كاربر هستند كه در برخى از پيادهسازىهاى CF به دليل اينكه دريافت رتبهبندى از كاربران به سادگى امكانپذير نمىباشد از دادههايى كه كاربر در هنگام مشاهده صفحات از خود به جا مىگذارد براى ارائه پيشنهادات استفاده مىشود. مانند روند بازديد صفحات و مدت زمان مشاهده اقلام مختلف ارائه شده در وب سايت. دسته دوم دادههاى دريافت شده از خود كاربر هستند كه كاربران ممكن است با مشخص كردن علاقهمندىهاى خود در هنگام خريد كالاهاى قبلى و دادن رتبه به هركدام به سيستم CF اجازه دهند تا پيشنهادات دقيقترى را به آنها ارائه دهد. به عبارت ديگر كاربران در هنگام خريد كالاهاى خود نظر خود را در ارتباط با آن كالا به صورت بازخورد طريق رتبهدهى در سيستم ثبت مىنمايند. CF در پيشنهادهاى آينده خود از اين اطلاعات استفاده كرده و كالاهاى جديد را مطابق با علایق كاربر پيشنهاد مىدهد. دادههاى استخراج شده از خود كاربر بسيار دقيقتر از دادههاى استخراج شده از رفتار كاربر مىباشند زيرا كاربر نظر خود را دقيق اعلام مى نمايد.
الگوريتمهاى متداول CF
در قسمت قبل به نحوه استخراج پيشنهادات اشاره شد كه براى استخراج بيشنهادات از دو روش مبتنى بر حافظه و مبتنى بر مدل استفاده مىشود. در اين قسمت به سه نمونه از الگوريتمهاى متداولى كه براى استخراج دادهها استفاده مىشود اشاره مىكنيم.
الگوريتم تصادفى: در اين روش به ازاى هر كاربر U و هر كالاى I يك عدد تصادفى ايجاد مىشود كه در هر اجرا همواره ثابت است. به عبارت ديگر در هر بار تلاش براى گرفتن پيشنهادات الگوريتم به كاربر و كالا عدد تصادفى يكسان با دفعات قبل اختصاص میدهد. این روند این قابلیت را میدهد که پیشنهادات به طور تصادفی ایجاد شود ولی در اجراهای متفاوت نتایچ یکسانی بدست آید. این الگوریتم در دسته الگوریتمهای مبتنی بر مدل جای میگیرد.
الگوریتم میانگین: در این روش برای هر کالا میانگین رتبهای که دیگر کاربران به آن دادهاند محاسبه میشود و با توجه به درخواست کاربر برای مشاهده نتایج تعداد K عدد از بیشترین میانگینها پیشنهاد میگردد. این الگوریتم در دسته الگوریتمهای مبتنی بر مدل جای میگیرد.
الگوریتمهای بر پایهی همسایگی: یکی از معروفترین و پر استفادهترین الگوریتمهایی که در CF استفاده میشود الگوریتمهای بر پایه همسایگی میباشد. در این الگوریتمها سعی میشود تا کاربرانی که علایق مشترکی با کاربر فعلی دارند ابتدا جستجو شوند و سپس کالاهایی که آن کاربران قبلا تهیه کردهاند به کاربر فعلی پیشنهاد میشود. این الگوریتم با بررسی کالاهایی که کاربر فعلی و دیگر کاربران به طور مشترک خریداری کردهاند به این نتایچ دست پیدا میکند. در پیاده سازی این الگوریتمها از دو راهکار متداول استفاده می شود:
کاربر به کاربر: این الگوریتمها در هنگام ارائه پیشنهاد به کاربر فعلی ابتدا در ماتریس ارزیابی کاربران دیگری که علاقهمندیهای مشابهی را در خریدهای گذشته خود نسبت به این کاربر فعلی داشتهاند را جستجو کرده و سپس کالاهایی که این کاربران در گذشته انتخاب کردهاند را پیشنهاد میدهند.
کالا به کالا: این الگوریتمها در هنگام ارائه پیشنهادات ابتدا کالاهایی که کاربر فعلی قبلا انتخاب کرده است را بررسی کرده و سپس با توجه به کاربرانی که قبلا نیز این کالاها را انتخاب کردهاند کالاهای دیگری که آن کاربران نیز انتخاب کردهاند را پیشنهاد میدهند. به عبارت دیگر ابتدا ماتریسی ارزیابی محدود به کاربرانی میشود که کالاهای مشترک را انتخاب کردهاند سپس تناظر بین کاربران و کالاهای خریداری شده انجام می پذیرد. یکی از متداول ترین معیارهایی که در بدست آوردن تشابهات استفاده میشود ضریب وابستگی پیرسون است. این ضریب، رابطه خطی بین دو متغیر مشخص می کند، حدی که دو متغیر با هم رابطه دارند و مقدار آن از - 1 تا + 1 متغیر است. مقدار +1 نشان دهنده ارتباط کامل دو متغیر و مقدار - 1 نمایش دهنده عدم ارتباط دو متغییر است. به عبارت دیگر + 1 نمایش میدهد که دو کاربر کاملا علایق مرتبط با هم دارند در صورتی که عدد - 1 نمایش دهنده تضاد علایق دو کاربر است. رابطه بین کاربر فعال a و کاربر دیگر u به شرج زیر است:
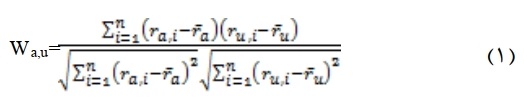
در جدول 1، جدول تحلیلی ضریب وابستگی پیرسون نشان داده شده است:
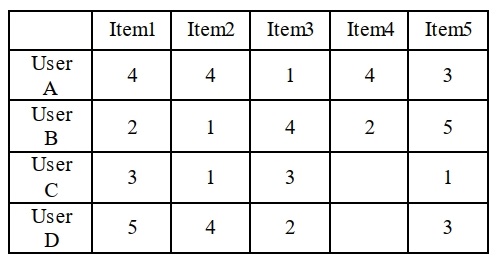
چه عددی بین 1تا 5 مشخص کننده علاقه کاربر D به خرید کالای 4 میباشد؟ ra میانگین رتبه دهی کاربر D برابر 5.3 است. ru میانگین امتیاز دهی دیگر کاربران است که برای کاربران B، A و C به ترتیب برابر 3، 3 و 2 است. (دقت شود فقط کاربرانی را در نظر می گیریم که مانند کاربر فعال کالاهای 1 ،2، 3 و 5 را نیز خریداری کردهاند.) n یعنی تعداد کالاهای مشترک برابر 4 میباشد. ra,i رتبهای است که کاربر فعال به کالای I داده است. ru,i رتبهای است که دیگر کاربران به کالای i دادهاند. با محاسبه فرمول مطابق دادههای جدول بدست میآوریم:
کاربران D و A بیشترین تشابه را دارا میباشند: WD,A=0.9 این مقدار عددی بیشتر به +1 نزدیک است. کاربران D و B کمترین تشابه را دارا میباشند: WD,B=-0.7 این مقدار عددی بیشتر به -1 نزدیک میباشد. این مقادیر بیانگر تشابه سلیقه کاربر D و A و عدم تشابه سلیقه کاربر D و B میباشد.
مشکلات CF
شروع سرد: الگوریتمهایی که بر اساس همسایگی مطرح شد تنها هنگامی به خوبی عمل میکنند که دادههای زیادی وجود داشته باشند. به عبارت دیگر کاربران مختلف کالاهای مختلف را ارزیابی کرده باشند. در مواردی مانند خرید خانه که تنها یک کالا (خانه مورد نظر) وجود دارد خرید کالای مشابه توسط کاربران مختلف معنایی ندارد. در نتیجه ارزیابی کاربران قبلی از این کالا بدون معنی میباشد و سیستم هیچگاه این گونه کالاها را پیشنهاد نمیدهد. همچنین این مشکل برای کالاهایی که به تازگی به لیست اضافه شدهاند و هنوز هیچ کاربری آنها را ارزیابی نکرده است به وجود میآید.
کمبود نظرها: از جهت دیگر کاربران اغلب مایل به ارائه نظر خود در مورد کالاها نمیباشند. در نتیجه در ماتریسی ارزیابی بسیاری از خانهها خالی خواهد ماند.
مقیاسپذیری: به موازات اینکه دادهها افزایش پیدا میکند حجم محاسبات بر روی ماتریس ارزیابی نیز افزایش پیدا میکند که این مورد در سیستمهای online مشکل ساز ظاهر میشود.
حریم خصوصی: امنیت اطلاعات افراد یکی از مسائل مشکل آفرین در سیستمهای CF میباشد. اغلب کاربران مایل نیستند اطلاعات خود را در معرض عموم قرار دهند در نتیجه راهکارهایی برای امنیت اطلاعات بایستی ایجاد شود.
اعتبار دادهها: به مرور زمان علایق شخصی کاربران تغییر خواهد کرد. مشکل دیگری که در CF بایستی با آن روبه رو شد اعمال این تغییر علاقه کاربران در پیشنهادات جاری است.
اعتماد به سیستمهای پیشنهاد دهنده: اغلب کاربران مایلند بدانند در پیشنهادی که به آنها ارائه میشود چه معیارهایی در نظر گرفته میشود. در نتیجه بایستی با دلایل مناسب سیستمهای CF کاربران خود را قانع نمایند. به عبارت دیگر چگونگی انتخاب معیار برای ارائه پیشنهاد نقش بسیار حیاتی در سیستمهای پیشنهاد دهنده دارد.
اعتماد به دادههای موجود در سیستمهای پیشنهاد دهنده: وارد کردن دادههای نادرست توسط صاحبان کالاها میتواند روند پیشنهادات را از مسیر صحیح خود خارج نماید. سیستمهای CF بایستی طوری طراحی شوند که افراد سود جو نتوانند کاربران را تحت تاشیر دادههای نادرست قرار دهند.
راه حل
معرفی جاذبههای گردشگری از دیرباز تا به امروز برای افزایش تعاملات میان ملل مختلف، نشان دادن تمدن کشور و مهمتر از همه برای کسب درامد وجود داشته و هر کشوری با روشهای مختلفی، مکانهای گردشگری خود را معرفی مینمودند. در گذشته بیشتر، مکانهای گردشگری معروف و مهم مورد توجه قرار میگرفت و مناطق دور دست و ناشناخته از دید گردشگران مخفی میماند. با گذشت زمان و پیشرفت تکنولوژی، دفاتر گردشگری ایجاد و راهنمایان گردشگری مناطق دیگری را به لیست گردشگری اضافه و معرفی نمودند، با پیشرفت تکنولوژی وب و گوشیهای هوشمند، گردشگران تنها با چند کلیک میتوانند مناطق گردشگری یک کشور، یک شهر و حتی بک منطقه را به راحتی پیدا و اطلاعات آنها را به دست آورد. در این تحقیق نیز بر اساس تکنولوژی روز، مناطق گردشگری مختلفی با استفاده از الگوریتمهای هوشمند، به گردشگران کمک میکند که مکانهای جذاب گردشگری را بر اساس علایق خود پیدا کنند. بر اساس فیلترهای استفاده شده در این مناطق گردشگری تقسیمبندی و بر اساس اطلاعات وارده گردشگر، مکانهای مورد نظر پیشنهاد و بر روی نقشه نشان داده میشود.
همچنین در تحقیقی به بررسی و معرفی مناطق گردشگری اطراف مکان گردشگری جذاب توریستی پرداخته شده است. کارکرد اصلی این سیستم بدین صورت است که وقتی گردشگری مقصد مورد نظر خود را انتخاب میکند، سیستم بر اساس پایگاه دادههای موجود خود مکانهای گردشگری در راستای مقصد گردشگری توریسم پیشنهاد میدهد در این سیستم با استفاده از علایق کاربر و مقصد انتخابی مکانهای نزدیک به مقصد را برای معرفی بیشتر و جذب گردشگر معرفی میکند. این سیستم موجب معرفی هر چه بهتر مکانهای ناشناخته و برای افزایش توریسم و درآمد زایی کاربرد دارد. این سیستم از سامانه GIS بهره میبرد. هدف، بررسی توزیع فضایی جذابیت گردشگری در شهرستانهای رومانی با در نظر گرفتن اجزای اصلی عرصه گردشگری از جمله جاذبه های توریستی، واحدهای اقامتی و خدمات پذیرایی از طریق یک رویکرد مبتنی بر GIS است.
مطالعه بر پایهی چارچوب دارای سه هدف اصلی است که ساختار این تحقیق را دنبال میکند:
- جمع آورى دادههاى فضايى مربوطه با توجه به رتبه كيفى رسانههاى اجتماعى از نقطه نظر ميزان علاقه (ميراث گردشگرى)، محل اقامت و خدمات پذيرايى.
- محاسبه تجزيه و تحليل مكانى در داخل منطقه شهرى براى دادههاى فضايى مربوطه.
- برجسته كردن الگوهاى فضاى شهرى ديكته شده توسط تامين گردشگرى كه هر دو توسط نقاط مورد علاقه و زيرساخت ارائه شده است.
در اين نمودارها مقايسهاى روش پيشنهادى با روشهاى معمول فيلترينگ سيستمهاى پيشنهادى:
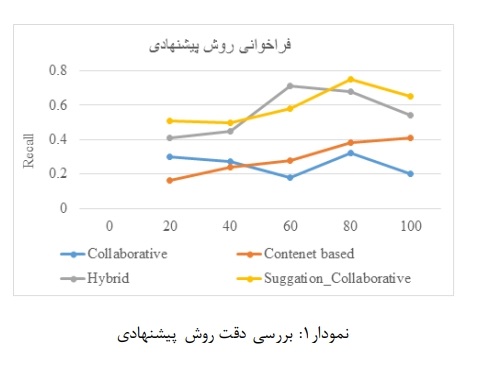
ميزان دقت فيلترينگهاى سيستم پيشنهاد دهنده را بر اساس عملكرد آنها و ميزان پيشنهادات بر اساس دقت نشان مىدهد. همانطور كه در نمودار مشخص است در حالت اوليه فيلترينگ مشاركتى به دليل برخى مشكلات در اين فيلترينگ درصد دقت نسبت به نمونههاى ديگر پايين مىباشد ولى در روش پيشنهادى (حذف شروع سرد با استفاده از پايگاه داده اوليه، بهره گيرى از رابطه وابستگى پيرسون) كه در اين تحقيق صورت گرفته دقت تشخيص به مراتب بهتر و كارآمدتر شده است. در روش پيشنهادى با افزايش تعداد كاربران كاهش چشمگيرى نسبت به نمونههاى ديگر مشاهده نمىشود. درصد بهبود فيلترينگ روش پيشنهادى نسبت به فيلترينگ اصلى 84% مىباشد. نمونه درصد دقت در مقالات مشابه قابل مشاهده است.
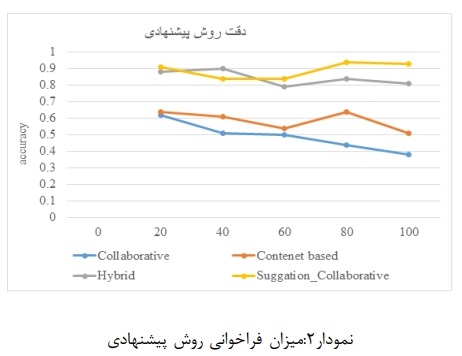
ميزان فراخوانى انواع فيلترينگهاى موجود در سيستم پيشنهاد دهنده را نشان مىدهد. با توجه به نمودار ميزان فراخوانى روش پيشنهادى نسبت به روش اصلى فيلترينگ مشاركتى به ميزان قابل توجهى افزايش يافته، دليل اين افزايش نيز بهرهگيرى از متدها و فرمولهاى به كار رفته در سيستم پيشنهاد دهنده گردشگرى مىباشد. درصد افزايش در حدود 94% مى باشد. نمونه درصد فراخوانى در مقالات مشابه قابل مشاهده است.
نتيجه گيرى
سيستم پيشنهاد دهنده با توجه به بعضى پارامترها، روشها، فيلترها، الگوريتمها و سيستمهاى موقعيت ياب پياده سازى شده است كه هر كدام بنابه شرايطى داراى مزايا و معايبى مىباشد، در اين تحقيق سعى شده است از بهترين پارامترها براى پيشبرد و ايجاد كارائى بالا در سامانه استفاده گردد. علم در جهان روز به روز درحال گسترش مىباشد، شايد در سالهاى آينده فيلترينگهاى بهتر و يا سامانههاى پيشنهاد دهنده كارآمدترى معرفى كردند. از اين رو مىتوان الگوريتمهاى جديدى كه در آينده براى انتخاب بهتر و گزينش علايق كاربران معرفى مىكردند در اين سامانه بهره برد و موجب بهبود هرچه بهتر آن شد. همچنين مىتوان روشهاى معرفى شده در اين تحقيق را براى سيستمهاى پيشنهاد دهنده ديگرى از جمله: مسيرهاى جادهاى، محصولاتى فروشگاهى و هر موردى كه نياز به انتخاب از ميان انتخابهاى مشابه بر اساس علايق كاربر باشد با كمى تغيير بهره برد.
و در آخر:
در این قسمت توضیحاتی آموزنده در مورد سیستم پیشنهاد دهنده گردشگری مبتنی بر فیلترینگ مشارکتی با استفاده از تصاویر دارای برچسب جغرافیایی گذاشته شد. در آینده مطالب بیشتری را در اختیار شما قرار خواهیم داد، با آرزوی بهترینها برای شما خواننده محترم.
منابع:
سمیه مجیر، دکتر قمرناز تدین و دکتر حسن شاکری، "سیستم پیشنهاد دهنده گردشگری مبتنی بر فیلترینگ مشارکتی با استفاده از تصاویر دارای برچسب جغرافیایی".

دیدگاههای بازدیدکنندگان
مقاله خوبی بود
558 روز پیش ارسال پاسخ