





مقدمه
انتخاب ویژگی یکی از مهمترین و پرکاربردترین تکنیکها در پیش پردازش برای دادهکاوی میباشد که در کاهش تعداد ویژگیها، رفع کردن ویژگیهای غیرمرتبط، برطرف کردن دادههای تکراری یا از بین بردن نویز در دادهها، استفاده میشود.انتخاب ویژگی تاثیرات ضروری و آنی مناسبی را برای برنامههای دادهکاوی مثل سرعت بخشیدن به الگوریتمهای دادهکاوی، ارتقاء کارایی دادهکاوی در دقتهای پیشگویانه و بالا بردن قابلیت درک نتایچ، بازیابی الگوهای آماری و یادگیری ماشین فراهم میآورد. همچنین در بسیاری از زمینهها از قبیل استفادهی گسترده در طبقهبندی متون، بازیابی تصاویر،مدیریت ارتباط با مشتری، کشف حمله در شبکه و تحلیل ژنها در علوم پزشکی کاربرد دارد. یکی از کاربردهای مهم انتخاب ویژگی، متنکاوی واستخراج دانش از متنها است. به دلیل افزایش متغیرهای مربوط به یک مشاهده نیاز به پیش پردازش قبل از پردازش داده بسیار اهمیت پیدا کرده است. انتخاب ویژگی از مهم ترین روشها و تکنیکها جهت پیش پردازش برای کاوش دادههاست. انتخاب ویژگی تاثیرات مناسبی را برای برنامههای دادهکاوی به همراه دارد به طوری که باعث بالا رفتن سرعت الگوریتمهای دادهکاوی، بالا رفتن دقت پیشگویی، قابلیت درک نتایچ، بازیابی الگوهای آماری و بهبود در یادگیری ماشین، مخصوصا در جریان دادههای بزرگ را فراهم میآورد. به دلیل تعدد زیاد ویژگیها در یک مجموعه داده، حجم مدل، بسیار بزرگ میشود. برای مقابله با این مشکل یک روش عمومی به نام انتخاب ویژگی وجود دارد. وجود آنتروپی فازی تاثیر زیادی بر روی ورودیهای روش پیشنهادی گذاشته است اما باعث نشده که میزان دقت از مرز میزان پیشبینی صورت گرفته در مدل دادههای خام فراتر رود و در عین حال این نتایچ نسبت به نتایچ مقاله واقعی نسبت به ورودی کل دادهها مناسبتر است و این نشان دهنده برتری مدل نسبت به روشهای دیگر است. که هدف ما از ارائه این روش میباشد.
پیشینه تحقیق
برای مساله انتخاب ویژگی، راه حلها و الگوریتمهای فراوانی ارائه شده است که بعضی از آنها قدمت سی یا چهل ساله دارند. مشکل بعضی از الگوریتمها در زمانی که ارائه شده بودند، بار محاسباتی زیاد آنها بود، اگر چه امروزه با ظهور کامپیوترهای سریع و منابع ذخیره سازی بزرگ این مشکل، به چشم نمیآید ولی از طرف دیگر، مجموعههای دادههای بسیار بزرگ برای مسائل جدید باعث شده است که همچنان پیدا کردن یک الگوریتم سریع برای این کار مهم باشد. بسیاری از محققان به انتخاب ویژگی پرداختهاند، تا سرعت طبقهبندیها در مسائل دادهکاوی بیشتر شود. برای روشهای انتخاب ویژگی، میتوان از جستجوی کامل، جستجو اکتشافی و فرا ابتکاری استفاد کرد. در این بخش به بررسی پژوهشهای انجام شده در سالهای اخیر پرداخته میشود.
احمدی زر و همکارانش در سال ۲۰۱۲ به ارائه روشی بر پایه ترکیب آنترویی فازی و کلونی مورچگان پرداختند. آنتروپی فازی، در واقع ترکیب فرمول آنتروپی و فازی میباشد که در ابتدا بر روی مجموعه داده صورت گرفته و ویژگیهای اضافی از مجموعه داده تشخیص داده شده و از معکوس این فرمول به عنوان تابع ارزیاب کلونی مورچگان استفاده شده و در فرمول فرومن جایگذاری کرده و هر ویژگی به عنوان یک گره از گراف در نظر گرفته شده و مورچگان با توجه به دیتاست بر روی این مسیر عبور کرده و فرومنی را برجای میگذارند که در نهایت مسیرهای ویژگیهای برتر میزان فرومن بیشتری برجای میگذارد.
مورچهها بر اساس ماده شیمیایی به نام فرومون که از خود بر جای میگذارند باهم ارتباط برقرار میکنند. روشی به نام TACO برای حل مسائل فضای گسسته و پیوسته ارائه شده است. در این روش دو رشته از صفر و یکها داریم که مورچهها از بین آنها گذشته و مسیری شامل صفر و یک میسازند. مورچهها در این فضا با توجه به هزینه مسیر ردپایی از خود بر جای میگذارند. این مسیر که یک راه حل پیشنهادی است توسط یک تابع هزینه ارزیابی می شود. برای پیاده سازی مساله انتخاب ویژگی با الگوریتم کلونی مورچه دو رشته صفر و یک به طول تعداد متغیرها در نظر میگیریم و الگوریتم را برای تشکیل رشتهای از صفر و یکها اجرا میکنیم. رشتهی بدست آمده توسط هر مورچه را رمزگذاری میکنیم که مقدار یک به معنی انتخاب ویژگی و مقدار صفر به معنی عدم انتخاب ویژگی میباشد.
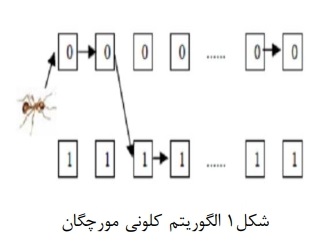
روش پیشنهادی برای بهبود الگوریتم روش BACO نام دارد که در آن مقدار مینیمم و ماکزیمم رد پای مورچهها بین دو مقدار Tmin و Tmax محدود شده و به مورچهای که بهترین تور را پشت سر گذاشته اجازه میدهد ردپا از خود به جا بگذارد. MTACO, TACO, K-NN پس از آزمایش و مقایسه با روشهای کارایی این روش تائید و موثرتر و کاراتر از دیگر روش هاست.
نکا و همکارانش در سال ۲۰۱۵ از ترکیب الگوریتم هارمونی و جست و جوی محلی تصادفی برای انتخاب ویژگیهای مناسب استفاده کردند. الگوریتم هارمونی از علم موسیقی گرفته شده است که در آن مجموعهای از راه حلها ایجاد شده و با استفاده از تابع ارزیابی این راه حلها با هم مقایسه شده و با هم ترکیب میشوند، روند کاراین الگوریتم به صورت الگوریتم ژنتیک میباشد با این تفاوت که از بین راه حلها همه را انتخاب میکند. برای بهبود این الگوریتم از الگوریتم جست و جوی محلی استفاده میشود که در واقع راه حلها در این روش محلی به صورت تصادفی تغییر میکنند.
در سال ۲۰۱۳ این روش برای مساله انتخاب ویژگی توسط موسوی راد و ابراهیم پور ارائه شد. در ابتدا امپراطوریهای اولیه تولید میشوند. در یک مساله N بعدی هر کشور آرایهای یک بعدی است که یک رشته از اعداد باینری را تشکیل میدهد به طوری که مقدار یک در یک خانه نشان دهندهی انتخاب ویژگی و مقدار صفر نشان دهندهی عدم انتخاب ویژگی میباشد. در شکل ۲ یک نمونه ارائه شده است.

براى آزمايش اين الگوريتم از پنج ديتاست Breast Pima Indians، Glass identification، cancer Iris، Diabetes استفاده شده است. پيشنهادى نشان مىدهد كه در همهى ديتاستهاى تست شده ICA دقت بالابى در مقايسه با الگوريتمهاى ديگر ايجاد كرد.
كاشف و همكارانش در سال ٢٠١٥ با استفاده از سيستم كلونى مورچگان مدلى براى كاهش ويژگیها در نظر گرفتند آنها در اين كار مورچهها را بر روى گراف قرار دادند بعد از اتمام تور طى كرده توسط هر مورچه در نهايت حاوى يك بردار كه شامل مقادير يك براى انتخاب آن ويژگى و مقادير صفر براى عدم انتخاب آن ويژگى مىباشد. در اين كار براى انجام مقايسه به ميزان دقت بالاتر در مجموعه داده توجه شده است.
روش پيشنهادى
يكى از روشهاى پوششى براى انتخاب ويژگى الگوريتم رقابت استعمارى است. الگوريتم رقابت استعمارى، همانند ساير روشهاى بهينهسازى تكاملى، با تعدادى جمعيت اوليه شروع میشود. در اين الگوريتم، هر عنصر جمعيت، يك كشور ناميده میشود. كشورها به دو دسته مستعمره و استعمارگر تقسيم میشوند. هر استعمارگر، بسته به قدرت خود، تعدادى از كشورهاى مستعمره را به سلطه خود در آورده و آنها را كنترل مىكند. سياست جذب و رقابت استعمارى، هسته اصلى اين الگوريتم را تشكيل میدهند. سياست جذب و رقابت استعمارى، هسته اصلى اين الگوريتم را تشكيل میدهند. در ارائه اين الگوريتم، اين سياست با حركت دادن مستعمرات يك امپراطورى، مطابق يك رابطه خاص صورت مىپذيرد. اگر در حين حركت، يك مستعمره، نسبت به استمارگر، به موقعيت بهترى برسد، جاى آن دو با هم عوض میشوند. در ضمن، قدرت كل يك امپراطورى به صورت مجموع قدرت كشور استعمارگر به اضافه درصدى از قدرت ميانگين مستعمرات آن تعريف مىشود. رقابت استعمارى، بخش مهم ديگرى از اين الگوريتم را تشكيل میدهد. در طى رقابت استعمارى، امپراطوریهاى ضعيف، به تدريج قدرت خود را از دست داده و به مرور زمان با تضعيف شدن از بين میروند. رقابت استعمارى باعث مىشود كه به مرور زمان، به حالتى برسيم كه در آن تنها يك امپراطورى در دنيا وجود دارد كه آن را اداره مىكند. اين حالت زمانى است كه الگوريتم رقابت استعمارى با رسيدن به نقطه بهينه تابع هدف، متوقف میشود. روش پيشنهادى از تركيب الگوريتم رقابت استعمارى و آنتروبى فازى تشكيل شده است كه در ادامه روند گام به گام آن شرح داده خوهد شد.
در روش پيشنهادى در ابتدا از معيار آنتروبى فازى، براى تشخيص ويژگیهاى قوىتر استفاده میشود.در ابتدا بايد تعيين كرد كه كدام ويژگیها مهمتر هستند. دانستن اين موضوع در نهايت مىتواند تاثير بسزايى بر شروع الگوريتم داشته باشد. به جهت تعيين ويژگیهاى تاثير گذار، از مفهومی به نام آنتروبى فازى استفاده میشود. در صورت محاسبه آنتروبى فازى، ويژگیهايى كه ميزان آنتروبى بالاترى دارند از مجموعه ويژگیها حذف شده و بقيه ويژگیها به عنوان ورودى الگوريتم رقابت استعمارى تعيين میشوند. بعد از اعمال آنتروبى فازى، ويژگیهايى با ميزان آنتروبى بالاتر از مجموعه ويژگیها حذف میشوند وسپس اين ويژگیها وارد الگوريتم رقابت استعمارى مىشوند. انجام اين پيش پردازش در ابتداى رقابت استعمارى، باعث حذف تصادفى بودن اين الگوريتم خواهد شد و همچنين برخى از مراحل اوليه كه شامل ويژگیهاى اضافه است را، حذف خواهد كرد.
براى شروع الگوريتم، تعداد Ncountry كشور اوليه ايجاد میشود. Ni تا از بهترين اعضا اين جمعيت (كشورهاى داراى بهترين مقدار تابع هزينه) به عنوان امپرياليست انتخاب میشوند. باقيمانده Ncol تا از كشورها، مستعمراتى را تشكيل میدهند كه هركدام به يك امپراطورى تعلق دارند. براى تقسيم مستعمرات اوليه بين امپريالستها، به هر امپرياليست، تعدادى از مستعمرات که این تعداد، متناسب با قدرت آن است، تعلق میگیرد. شکل ۳ فلوچارت روند پیشنهادی را نشان میدهد.
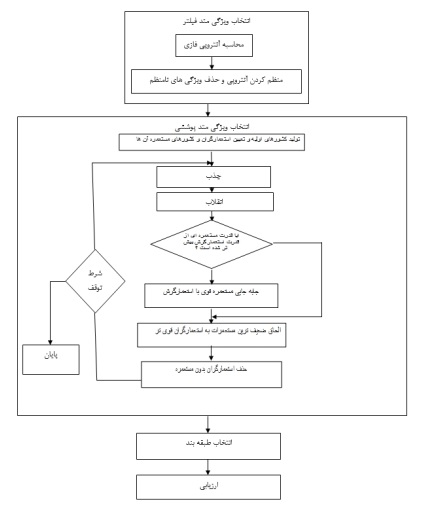
شکل ۳ فلوچارت روند پیشنهادی
1. الگوریتم رقابت استعماری پیاده سازی شده
در این بخش رویکرد انتخاب ویژگی با استفاده از الگوریتم رقابت استعماری ارائه شده است. مراحل رویکرد پیشنهادی به صورت زیر میباشد.
- ایجاد امپراتوریهای اولیه: در یک مسئله N بعدی، یک کشور یک آرایه N*1 است. در رویکرد پیشنهادی، هر کشور یک رشته از اعداد دوتایی است. وقتی ارزش یک سلول از کشور ۱ است، این ویژگی انتخاب شده است و زمانی که ۰ است، این ویژگی انتخاب نشده است. الگوریتم با N pop آغاز میشود که در واقع شامل کشورهایی است که جمعیت آنها را تشکیل میدهند و بهترین آنها به عنوان امپریالیست انتخاب میشود. برای تشکیل امپراتوریهای اولیه، مستعمرات در میان امپریالیستها بر اساس قدرت آنها تقسیم میشوند.
- جذب: پس از ایجاد امپراتوری اولیه، کشورهای امپریالیستی برای بهبود مستعمرات خود شروع به کار میکنند. برای این منظور، مستعمرات شروع به حرکت به سمت امپریالیستی خود بر اساس سیاست جذب نسخه اصلی رقابت استعماری صورت میگیرد. برای هر یک از امپریالیستها و مستعمرات آنها فاصله بین کلونی و امپریالیست آنها محاسبه میشود. ما نمیخواهیم دقیقا به موقعیت امپریالیست دست یابیم زیرا میخواهیم موقعیتهای جدیدی را پیدا کنیم بنابراین این فاصله را در یک ضریب انحراف ضرب میکنیم. بنابراین موقعیت جدید برای هر کلونی برابر خواهد بود با موقعیت قدیم آن کلونی بعلاوه فاصله کلونی تا امپریالیست در یک ضریب انحراف.
- انقلاب: عملیات انقلاب در الگوریتم رقابت استعماری شبیه به عملیات جهش در الگوریتم ژنتیک میباشد. در اینجا تغییرات روی کل درایهها صورت نمیگیرد و در اینجا تعدادی از درایهها در کلونیها یا امپریالیستها به صورت تصادفی انتخاب میشود و تغییرات روی آنها صورت میگیرد. عملیات انقلاب برای امپریالیستها و کلونیها به این صورت انجام میگیرد که برای امپریالیستها ما تغییرات را در صورتی اعمال میکنیم که در نهایت تابع رازندگی آن بهتر شود و در غیر این صورت تغییری ایجاد نمیکنیم. عملیات انقلاب برای کلونیها به این شکل است که در قسمت انقلاب یک پارامتر به نام احتمال انقلااب وجود دارد. در اینجا به این صورت عمل میکنیم که یک عدد تصادفی تولید میکنیم در صورتی که این عدد تصادفی کوچکتر از احتمال انقلاب بود، تعدادی درایه در کلونیها به صورت تصادفی انتخاب میشود و تغییرات روی کلونیها صورت میگیرد.
- به روز رسانی امپریالیسم: پس از انجام عملیات انقلاب و جذب، تغییرات بهبود کلونیها نسبت به امپریالیستها بررسی میشود. به این شکل که برای همه امپراطوریها و به ازای تمام کلونیهای موجود در آنها، بین کلونیها و امپریالیست از لحاط برازندگی مقایسه صورت میگیرد و در صورتی که برازندگی کلونی بهتر از امپریالیست باشد تعویض صورت میپذیرد.
- محاسبه کل هزینه امپرا توری: قدرت کامل یک امپراطوری به دو قدرت کشور امپریالیستی و قدرت مستعمرات آن بستگی دارد.
- حذف امپراتوریهای بی قدرت: یک امپراتوری وقتی که کل مستعمرهاش را از دست داد سقوط میکند. در این مورد، امپریالیسم به عنوان مستعمره در نظر گرفته شده و به امپراتوری دیگر اختصاص داده میشود.
- متوقف شدن معیارها: بعد از مدتی تمام امپراتوریها به جز قدرتمندترین آنها سقوط خواهند کرد. در چنین وضعیتی، همه مستعمرات برازندگی یکسان و موقعیت یکسانی دارند. که در چنین شرایطی، به رقابت امپریالیستی پایان داده و الگوریتم متوقف میشود.
- تابع برازندگی: برای محاسبه تابع هدف در اینجا ما چند هدف را باید دنبال کنیم یعنی علاوه بر این که باید تعداد ویژگیها را متعادل کنیم. باید میزان خطا را نیز پایین بیاوریم. پس در این جا بحث بهینه سازی هدف مطرح میشود. یکی از روشهای محاسبه مسائل بهینهسازی چند هدفه به این شکل است که میتوانیم این دو را به صورت وزن دار با هم جمع کنیم.
اگر تعداد ویژگیها را nf در نظر بگیریم خواهیم داشت:
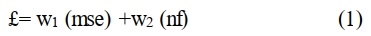
میخواهیم هر دو را کم کنیم بنابراین کل تابع هدف را به w1 تقسیم می کنیم بنابراین خواهیم داشت:

جابجایی w2/w1 که عددی مثبت است می توانیم عدد مثبت w را در نظر بگیریم و میدانیم که w میتواند با mes متناسب باشد یعنی:
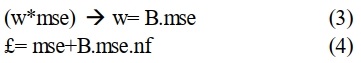 (در اینجا B یک عدد مثبت و مستقل از mse است.)
(در اینجا B یک عدد مثبت و مستقل از mse است.)
با افزایش nf مقدار mse کمتر میشود، یعنی این دو اثر یکدیگر را خنثی میکنند اما در اینجا B تعیین کننده به تعادل رسیدن nf و mse میباشد به عبارت دیگری هزینه افزودن ویژگی است. اگر B=0 باشد یعنی همه ویژگیها را در نظر گرفتهایم و اگر مقدار B خیلی بزرگ باشد اثر عدد ۱ خنثی میشود. بنابراین یک حالت میانی باید برای مقدار B انتخاب کنیم.
بحث و نتیجه گیری:
انتخاب ویژگی یکی از مهمترین و پرکاربردترین تکنیکها در پیش پردازش برای دادهکاوی میباشد که در کاهش تعداد ویژگیها، رفع کردن ویژگیهای غیر مرتبط، بر طرف کردن دادههای تکراری یا از بین بردن نویز در دادهها، استفاده میشود. انتخاب ویژگی تاثیرات ضروری و آنی مناسبی را برای برنامههای دادهکاوی مثل سرعت بخشیدن به الگوریتمهای دادهکاوی، ارتقاء کارایی دادهکاوی در دقتهای پیشگویانه و بالا بردن قابلیت درک نتایچ، بازیابی الگوهای آماری و یادگیری ماشین فراهم میآورد. همچنین در بسیاری از زمینهها از قبیل استفادهی گسترده در طبقهبندی متون، بازیابی تصاویر، مدیریت ارتباط با مشتری، کشف حمله در شبکه و تحلیل ژنها در علوم پزشکی کاربرد دارد. یکی از کاربردهای مهم انتخاب ویژگی در متنکاوی و استخراج دانش از متنها میباشد. روشهای کاهش ویژگی عبارتند از: 1.روش فیلتر، 2. روش پوششی 3.روش تعبیه شده
متدهای اولیه برای انتخاب ویژگی متدهای فیلترینگ بودند. روشهای فیلتر روشهایی هستند که با انجام مجموعهای از فرمولها به جواب میرسند. روشهای پوششی روشهایی هستند که با استفاده از یک الگوریتم استنتاجی به جواب می رسند. همه این الگوریتمها از تکنیک جستجوی مکاشفهای(در روشهایی با این نوع جستجو و در تمام الگوریتمهای فرامکاشفهای، در هر بار اجرای الگوریتم، تنها و به سادگی، هر بار یک ویژگی برای افزوده شدن کنترل نمیشود و مواردی مانند الگوریتم ژنتیک وجود دارد که یک نسل از انتخابها به نسل قبلی افزوده میشوند. به همین دلیل پیچیدگی زمانی آنها محدود و کمتر است. در این گونه موارد، اجرای الگوریتم خیلی سریع میباشد و پیاده سازی آنها نیز بسیار ساده است، استفاده میکنند. دسته سوم روشهایی هستند که مجموعهای از عملیاتها توسط خود الگوریتم صورت میگیرد و در آن مجموعهای از ویژگیها انتخاب میشوند، نمونهای از این الگوریتمها درخت تصمیم میباشد.
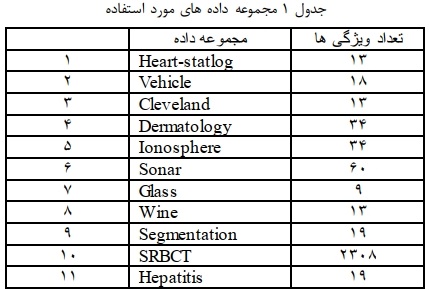
یکی از روشهای فیلتر برای انتخاب ویژگی آنتروپی میباشد. در روش پیشنهادی از ترکیب روش آنتروپی فازی و الگوریتم رقابت استعماری استفاده شده و عملیات انتخاب ویژگی صورت گرفته است. که نتایچ این پژوهش با مقاله پایه مقایسه شده است و نتایچ آنها نشان دهنده برتری این روش نسبت به روش مقاله پایه است. در این پژوهش نتایج الگوریتم knn به تنهایی بر روی مجموعه داده و knn با پیش پردازش آنتروپی فازی صورت گرفته است و نتایج کلی آنها با یکدیگر مقایسه شده است. وجود آنتروپی فازی تاثیر زیادی بر روی ورودیهای روش پیشنهادی گذاشته است اما باعث نشده که میزان دقت از مرز میزان پیشبینی صورت گرفته در مدل دادههای خام فراتر رود و در عین حال این نتایچ نسبت به نتایچ مقاله واقعی نسبت به ورودی کل دادهها مناسبتر است و این نشان دهنده برتری مدل نسبت به روشهای دیگر است. مجموعه دادههای متفاوتی در این پژوهش تست شده است که در جدول 1 نشان داده شده است. مجموعه 11 داده در این روند انتخاب شده و عملیات پیش پردازش انتخاب ویژگی بر روی آنها صورت خواهد گرفت، تعداد ویژگیهای این دادهها در حالت اولیه در جدول 1 مشخص شده است.
توجه به این مسئله که از طبقهبند kmn استفاده شده است، نتایچ آن در ادامه بیان شده است. با اعمال آنتروبی فازی تعداد ویژگیهای کاسته شده و به صورت جدول 2 نشان داده شده است. همان طور که مشخص است بعد از محاسبه آنتروپی 30 درصد از ویژگیهایی که آنترویی آنها بالاتر از مقدار میانگین کل آنتروبیها بودند، در این دادهها حذف شدند. 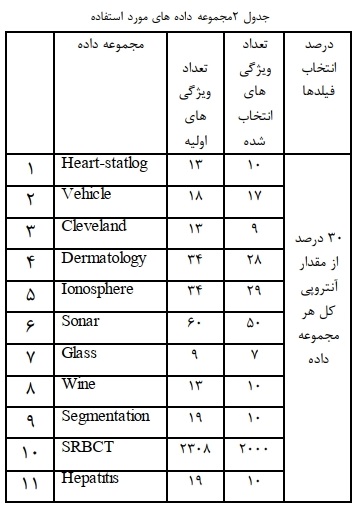
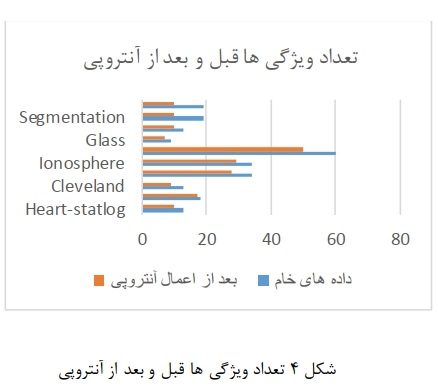
همان گونه که در جدول 2 مشاهده میشود با استفاده از پیش پردازش آنتروپی به تعداد ویژگیهای تعیین شده از مجموعه داده حذف صورت میگیرد. تعداد ویژگیها در حالت اولیه و حالت نهایی در شکل 4 نشان داده شده است.
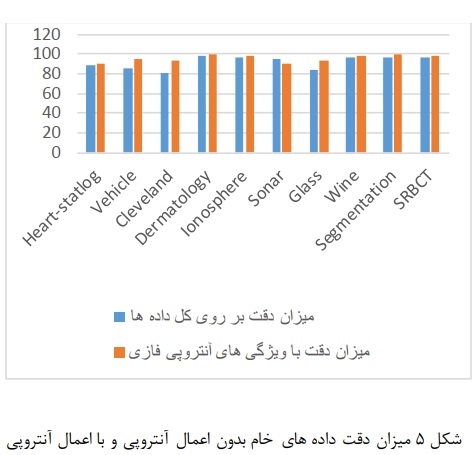
ميزان دقت دادههاى خام بدون اعمال آنتروبى و با اعمال آنتروبى در شكل 5 نشان داده شده است:
در شكل 6، ميزان دقت روش پيشنهادى و مقاله مرجع، نمايش داده شده است كه اين نمودار نشان دهنده برترى اين روند نسبت به روند مقاله مرجع است.
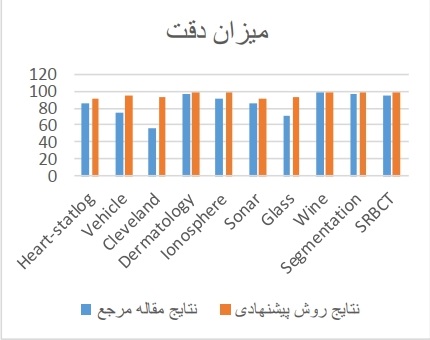
شكل 6 ميزان دقت روش بيشنهادى و مقاله مرجع
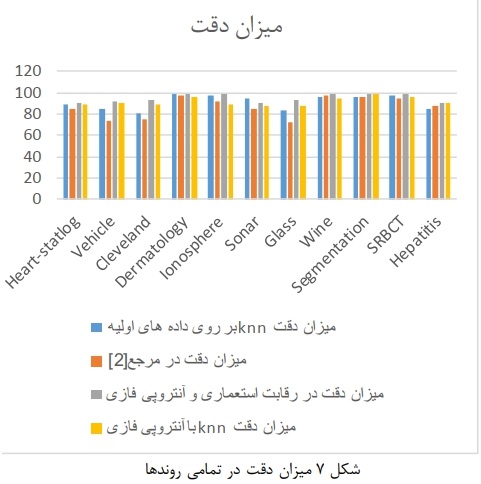
ميزان دقت در اين دادهها در جدول 3 نمايش داده شده است، همان طور كه مشخص است نتايج بدست آمده از روش پيشنهادى حدوداً نزديك به روش استفاده از كل دادههاست كه اين نتايج نشان مىدهد كه بدون تغير زياد ميزان دقت در كل دادهها و روش پيشنهادى نيز با كاهش ويژگى به همان نتايج خواهد رسيد. در اين جدول ميزان دقت kmn بر روى كل دادهها، با دادههاى انتخابى آنتروبى فازى و مقاله مرجع و روش پيشنهادى نمايش داده شده است. 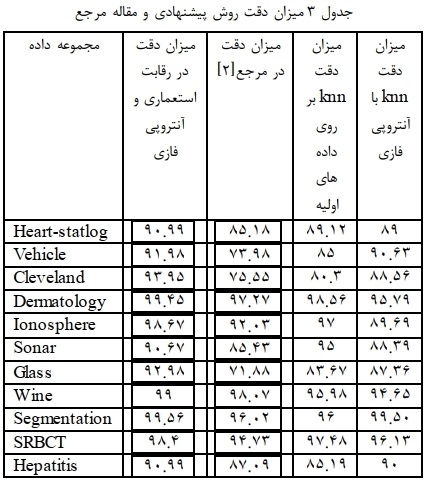 شکل 7 میزان دقت روشها را در یک نمودار واحد نشان خواهد داد. در هر کدام از این دادهها نتایج نشان داده شده است و همانطور که مشخص است روش پیشنهادی در این رویکرد بهترین روند را دارد.
شکل 7 میزان دقت روشها را در یک نمودار واحد نشان خواهد داد. در هر کدام از این دادهها نتایج نشان داده شده است و همانطور که مشخص است روش پیشنهادی در این رویکرد بهترین روند را دارد.
و در آخر:
در این قسمت توضیحاتی آموزنده در مورد انتخاب ویژگی با استفاده از الگوریتم رقابت استعماری و معیار آنتروپی گذاشته شد. در آینده مطالب بیشتری را در اختیار شما قرار خواهیم داد، با آرزوی بهترینها برای شما خواننده محترم.
منابع:
عاطفه مهتابی، دکتر الهام پروینیا، "انتخاب ویژگی با استفاده از الگوریتم رقابت استعماری و معیار آنتروپی".

دیدگاه خود را بنویسید