





مقدمه:
تعداد بد افزارها هر روزه به طور چشمگيرى در حال افزايش است، همچنين توليدكنندگان بد افزارها از تكنيکهاى پيشرفته برنامهنويسى و روشهاى نوين اختفا از جمله تكنيكهاى مبهم سازى، رمزگذارى، استراتژیهاى چند شكلى و استراتژیهاى دگرگون شونده و غيره در توسعه بدافزارهاى خود استفاده مىكنند و همين امر، عمليات شناسايى بدافزارهاى نوظهور را به امرى بسيار دشوار و چالش برانگيز بدل كرده است. اين پيشرفتها در توسعه بد افزارها از يك سو، همچنين اهميت امنيت سيستمهاى كامييوترى از سوى ديگر، مقابله با اين تهديد بزرگ را به يكى از مباحث به روز در حوزه امنيت سيستمهاى كامپيوترى تبديل كرده است، لذا باتوجه به ضررهاى مالى ناشى از اين كمبود ساخت يا طراحى متدهاى جديد براى آناليز و شناسايى بد افزارها غيرقابل اجتناب است. حملات جديد به راحتى متدهاى مبتنى بر امضاى رايج را دور مىزنند و متدهاى مبتنى بر رفتارهاى فعلى براى استفاده در نرمافزارهاى آنتى ويروس صنعتى داراى سرعت كم و ناكارآمد هستند، بنابراين نياز به ارائهى متدى كارا احساس مىگردد. يرداختن به تشخيص بد افزارها زمينهاى است كه جاى كار پژوهشى بسيارى براى آن مىتوان متصور شد. اما در راستاى تشخيص بد افزار با چالشهايى روبه رو هستيم. يكى از چالشها تشخيص به موقع بدافزار مىباشد. همچنين ظهور و بروز بد افزارهاى نسل جديد از جمله بد افزارهاى مبتنى بر رويدادها و داراى چند انشعاب، هوشمندتر شدن انواع روشهاى دگرديسى و ساير روشهاى جديد، از ديگر چالشهاى تشخيص بد افزار مىباشد. از طرفى منابع مورد استفاده توسط روشهاى تشخيص، در بعضى موارد توسط بد افزارها مورد حمله قرار گرفته و در نتيجه منجر به غيرفعال شدن روش تشخيص مىگردند. همچنين بايستى در نظر داشت كه بيشتر كارهاى صورت گرفته در تشخيص و توليد امضاء بد افزارها از منابع سيستمى استفاده مىكنند. اين روشها رفتار زمان اجراى برنامهها را به وسيلهى جريان داده، توالى فراخوانىهاى سيستمى توصيف نموده و سپس تشخيص را صورت داده و در صورت امكان توليد امضاء مىكنند. با توجه به سربار بالاى اين روشها، در عمل پیادهسازی آنها مشكل مىباشند، كه هر يك از اين چالشها خود زمينه تحقيقاتى مناسبى میباشد.
تكنيكهاى شناسايى بد افزار
شناسايى بد افزار شاخهاى از امنيت سيستمهاى كامپيوترى است كه سعى در تشخيص، تحليل و مقابله با انواع بد افزارها دارد. روشهاى مختلفى براى تشخيص بد افزارها وجود دارد اما با توجه به پيچيدهتر شدن بد افزارها توسط تكنيكهاى مبهم سازى نياز به روشهاى ييشرفتهترى براى تشخيص آنها مى باشد. تحقيقات انجام شده باعث به وجود آمدن روشهاى نوينى در شناسايى بدافزارها شده است كه به طور كلى اين روشها را میتوان به سه گروه كلى روشهاى شناسايى مبتنى بر امضاء، روشهاى شناسايى ناهنجارى و روشهاى مكاشفهاى شناسايى بد افزار تقسيم بندى كرد كه در ادامه به بررسى هر يك میپردازيم.
1. روشهاى مبتنى بر امضاء
روشهاى مبتنى بر امضاء، روشهاى سنتىاى است كه بر پايه پايگاه دادهاى از امضاءهاى استخراج شده از بدافزارهاى شناخته شده، استوار هستند. امضاى يك بدافزار دنبالهاى از بايتهاى درون فايل بدافزار است كه منحصر به فرد بوده و در فايل ديگرى يافت نشود. در اين روشها كه در بين آنتى ويروسهاى تجارى بسيار معمول هستند، از پايگاه دادههايى از امضاءهاى بدافزارها استفاده مىكنند به اين صورت كه هنگام مواجهه با هر فايل، وجود يا عدم وجود امضاى استخراج شده از آن فايل در پايگاه داده مورد بررسى قرار مىگيرد و در صورت بروز تطابق دقيق امضاى فايل با هر يك از امضاهاى موجود در پايگاه داده، فايل مورد نظر به عنوان بدافزار شناسايى میشود. اگرچه روشهاى شناسايى مبتنى بر امضاء دقت و كارآمدى خود را در تشخيص بدافزارهاى از پيش شناسايى شده به اثبات رساندهاند، اما در شناسايى بدافزارهاى جديد و ناشناخته بسيار ناتوان هستند. همچنين استفاده از روشهاى مبتنى بر امضاء بسيار پرهزينه میباشد، چرا كه استفاده از اين روشها مستلزم شناسايى اوليه، تحليل دقيق، استخراج امضاء و نهايتاً اضافه كردن امضا به پايگاه دادهها مىباشد كه انجام اين مراحل داراى هزينه بسيار زياد مالى و زمانى است و اين فرصت را در اختيار بدافزار قرار میدهد كه در سطح وسيعى گسترش يافته و موجب آسيبهاى فراوانى گردد.
2. روشهاى شناسايى ناهنجارى
شناسايى ناهنجارى يعنى پيدا كردن الگوهاى خاصى در دادهها كه رفتار آنها با رفتارى كه از آنها انتظار میرود مطابقت ندارد، روشهاى شناسايى ناهنجارى سعى در يادگيرى رفتارهاى طبيعى برنامههاى كامپيوترى دارند. بس از انجام عمليات يادگيرى، در صورت مشاهده هر گونه رفتار غير طبيعى عامل بروز آن را به عنوان مورد مشكوك معرفى مى كنند. نسبت مثبت نادرست بالا را مى توان به عنوان مهمترين مشكل موجود در اين روشها نام برد.
3. روشهاى مكاشفهاى
كاستیهاى روشهاى مبتنى در امضاء و ناتوانى آنها در شناسايى بدافزارهاى نوين و همچنين ميزان خطاى بالاى روشهاى شناسايى ناهنجارى باعث ظهور نسل جديدى از تكنيكهاى شناسايى با نام روشهاى مكاشفهاى شد كه اين روشها از ابزارهاى يادگيرى ماشين و داده كاوى جهت شناسايى بدافزارها استفاده مىكنند، روشهاى مكاشفهاى بر پايه مجموعهاى وسيع از دادههاى مرتبط با هر دو كلاس (خوش خيم و بدافزار) استوار هستند. اين روشها با استفاده از ويژگیهاى ساختارى استخراج شده از فايلهاى خوشخيم و بدافزار سعى در يادگيرى مدل رفتارى آنها و آموزش كلاسه كنندههاى يادگيرى ماشين دارند. اگر چه فراهم كردن اين حجم وسيع از دادههاى برچسب دار هميشه كار سادهاى نبوه و در برخى موارد غير ممكن است و همين امر به يكى از نقاط ضعف اين روشها تبديل شده است، اما از مهمترين مزاياى اين روشها میتوان به قابليت شناسايى بدافزارهاى ناشناخته و نوظهور اشاره كرد. شكل 1 ويژگىهاى ساختارى مورد استفاده در اين روشها را نمايش میدهد.
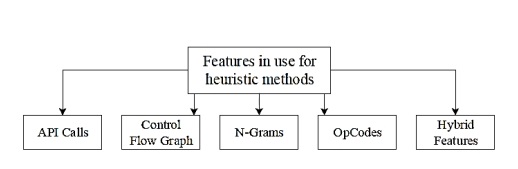
شكل 1- ويژگیهاى ساختارى مورد استفاده در روشهاى مكاشفهاى
همان طور كه در شكل 1 مشاهده مىشود، از جمله ويژگىهاى ساختارى كه در اين روشها مورد استفاده قرار میگيرند مىتوان به فراخوانىهاى توابع سيستمى، گراف كنترل جريان، N Gram ها، كدهاى عملياتى زبان اسمبلى و ويژگىهاى تركيبى اشاره كرد اين ويژگىهاى ساختارى از درون فايلهاى هر دو كلاس استخراج شده و به منظور آموزش داده كلاسه كنندههاى يادگيرى ماشين مورد استفاده قرار مىگيرند. در سالهاى اخير و با پيشرفت تكنيكهاى مكاشفهاى و نيز مزاياى قابل توجه آنها، اين روشها به طور گسترده مورد استفاده قرار گرفته و حتى جايگاه خود را در بين آنتى ويروسهاى تجارى نيز پيدا كردهاند. اين ويژگىهاى ساختارى به دو طريق، از دادههاى آموزشى استخراج میشوند. در ادامه به شرح آنها پرداخته مى شود.
تحلیل بدافزارها
به طور کلی دو رویکرد عمده برای آنالیز بدافزارها وجود دارد: آنالیز بر مبنای رفتار پویا و آنالیز بر مبنای خصیصههای ایستا. با وجود اینکه هر دو روش نحوه عملکرد بدافزار را شرح میدهند، اما ابزار، زمان و تخصص مورد نیاز برای هر کدام به طور چشمگیری با هم متفاوت است. جزئیات این دو تکنیک در ادامه شرح داده خواهد شد.
1. آنالیز ایستا
روش سنتی برای شناسایی بدافزار، (که به وسیله آنتی ویروسها به کار برده شده است) جستجوی آماری فایلهای اجرایی برای یافتن دنبالهای از رشتهها، دستورات یا الگوهایی است که میتوانند یک بدافزار را مدل نمایند. معمولا این رشتهها که نمایندهای از ویروس هستند را به صورت مستقیم از باینری بدافزارها یا دستورات تبدیل شده به کد ماشین استخراج میکنند. مستله این است که این قبیل از رشتهها به صورت معمول تنها مخصوص ساختار ظاهری یک نمونه بدافزار معین میباشند. آنالیز ایستا اطلاعاتی دربارهی کنترل برنامه، جریان داده، وابستگی دادهها و سایر مشخصههای آماری بدون اجرای واقعی باینری به ما میدهد. آنالیز امضای باینری، رایجترین روش آنالیز ایستای بدافزار میباشد. این روش شامل ایجاد یک امضا یا مدل است که یک قسمت از رفتار یا کد مخرب و برخی از گونههای آن را مدل میکند. این امضا برای توصیف کردن رفتارهای مخرب استفاده میشود. عموما فروشندگان آنتی ویروسها یک بانک اطلالاعاتی بزرگ از امضاهای از قبل بدست آمده را نگهداری میکنند. زمانی که یک امضا درون یک برنامه شناسایی میشود، این پتانسیل وجود دارد که برنامه به عنوان گونهای از خانوادهی بدافزاری باشد که امضاء، آن را نمایش داده است. از آن جایی که امضاها باید قبل از استفاده توسط ابزارهای اتوماتیک در پایگاه داده وجود داشته باشد بنابراین این روش قادر به شناسایی حملات و تهدیدات در همان روزهای ابتدایی پیدایش نیست. امضاها میتوانند اشکال گوناگونی به خود بگیرند اما غالبا چیزی جز یک عبارت منظم نیست که میتوانند تنوعی از توالی قسمتهای مختلف باینری را نشان دهند. ایجاد امضاها به طرق مختلفی میتواند صورت پذیرد. پخش عمدهای از فعالیتهایی که در این زمینه وجود دارد به دنبال یافتن بهترین راه برای ایجاد امضاها است به طوری که بهترین میزان پوشش و قابلیت استفاده مجدد را دارا باشد. از آنجایی که ایجاد امضاها توسط شرکتهای آنتی ویروسی اغلب به صورت دستی صورت می پذیرد، بنابراین با توجه به روند رو به رشد بدافزارها یافتن راهی برای خود کارسازی این فرایند بسیار ارزشمند است. ایدههای دیگری نیز برای آنالیز ایستای بدافزارها وجود دارد. این رویکردها اغلب از مفاهیم مربوط به داده کاوی و آمار برای مدل کردن الگوهایی از داده در باینری اجرایی استفاده میکنند. متدهایی از این قبیل تلاش میکنند که معنا و مفهومی از کدهای باینری فراتر از یک منظر تنوریک ایجاد کنند. این روشها الگوهای از کد برنامه را در نظر می گیرند و تلاش میکنند که مفاهیم و معانی آن کد را بدون اجرای آن درک کنند. از آن جایی که بدافزارها با استفاده از تکنیکهایی نظیر چند ریختی و مبهم کردن کد میتوانند شکل خود را تغییر دهند در حالیکه رفتارهای آنها بدون تغییر باقی میماند. در نتیجه به سادگی میتوانند از شناسایی توسط آنتی ویروسهای مبتنی بر امضا اجتناب کنند.
مزیت اصلی روشهای ایستا، قابلیت در نظر گرفتن تمامی مسیرهای ممکن برنامهها میباشد که این امر موجب دقت بیشتر در توصیف قابلیتهای برنامه میشود. همچنین این روش، احتیاج به منابع کمتری داشته و زمان کمتری را نسبت به روشهای دینامیک مصرف میکند. در نتیجه این روش برای آنالیز نرخ نمایی رشد بدافزار مناسب است. اما متاسفانه این روش قادر به تشخیص بدافزارهایی نیستند که از تکنیکهای بسته بندی در زمان اجرا و بسیاری از روشهای تبدیل به کد ماشین نشدن و معکوس ناپذیری، از قبیل رمزگذاری، فشرده سازی، تزریق کدهای بدردنخور، جایگشت کد و غیره استفاده میکنند. بنابراین دستورات باینریها بر روی دیسک با دستورات زمان اجرا متفاوت است. با وجود اینکه بازکنندهها گاهی در بازیابی دستورات واقعی کمک میکنند، هنوز هم آنالیز باینریهای مبهم شده بسیار دشوار بوده و می توان نشان داد که یک مستله NP-hard میباشد. از طرف دیگر، محققان برای فهمیدن عملکردهای بدافزارها به وسیلهی تحلیل ساختار بدافزار نیاز به زمان دارند.
2. آنالیز پویا
تکنیکهای آنالیز پویا برای شناسایی بدافزارها از تحلیل اجرای برنامه یا تاثیری که برنامه آلوده بر روی پلتفرم (سیستم عامل) دارد، استفاده میکنند. بیشتر سیستمهای آنالیز پویا، نمونههای بدافزار را در یک محیط مجازی یا امن اجرا کرده، سپس به مانیتور کردن اجرای آنها پرداخته و رفتارهای زمان اجرای آن ها را بر اساس API ها یا دنبالههای فراخوانیهای سیستمی استخراج مینمایند. در نهایت از این اطلاعات برای تحلیل شناسایی بدافزار استفاده میکنند. یکی از مزایای این روش این است که نیازی به حدس زدن اینکه یک برنامه رفتارهای مخرب خود را از خود نشان میدهد، تصمیم گیری میکند. از آن جایی که این روش احتیاج به دانش انحصاری دربارهی یک برنامه مخرب ندارد، بنابراین روش پویا قابلیت شناسایی برخی از تهدیدات و حملات در همان روزهای ابتدایی پیدایش را دارد.
مزیت اصلی آنالیز پویا این است که ویژگیهای رفتاری به تکنیکهای تغییر سطح پایین از قبیل بسته بندی زمان اجرا یا باینریهای مبهم شده حساس نمیباشد. به این دلیل که تغییرات در باینری بدافزارها به ندرت بر روی API ها یا فراخوانیهای سیستمی تائیر میگذارد. بعلاوه، روشهای مبتنی بر ویژگیهای رفتاری، به شناسایی رفتارهای بدافزارها میپردازد. در نتیجه این روشها این پتانسیل را دارا میباشد که هم زمان چندین خانواده از بدافزارها با یک رفتار مشابه را شناسایی کنند. با این وجود روشهای پویا نیز چندین محدودیت دارند. آنها تنها میتوانند رفتارهایی که بدافزار در آن اجرای خاص، نشان داده را شناسایی کنند و قادر به شناسایی تمامی قابلیتهای بدافزار نمیباشند. برای مقابله با این محدودیت، تکنیک ایجاد چند مسیره پیشنهاد شده است. در این روش، رفتارهای نمونههای بدافزار به صورت مداوم به وسیله بررسی چندین مسیر اجرایی مختلف در زمان اجرا مانیتور میشود. از طرف دیگر، آنالیز پویا از منابع زیادی استفاده میکند و به همین دلیل تنها میتوان هر نمونه را برای مدت زمان محدودی مانیتور کرد. که دراین زمان اکثر بدافزارها تمام رفتار مخربشان را نشان نمیدهند. همچنین این امکان وجود دارد که بدافزارها محیط مجازی که در آن اجرا میشوند را شناسایی کرده و رفتار مخرب خود را در زمان آنالیز نمایش ندهند که این امر باعث بالا رفتن نرخ مثبت کاذب میشود.
روشهای تشخیص بدافزار به صورت پویا
به روشی که در آن شناسایی بدافزار با اجرای فایل مورد نظر انجام گیرد، شناسایی پویا میگوییم. در این روش سعی بر این است که بدافزار در یک محیط مجازی اجرا شود و تمامی رفتارهای آن مورد بررسی قرار گیرد و در صورت مشکوک بودن رفتارهای فایل اجرا شده، ویروسی بودن آن اعلام شود. بنابراین در این بخش به مروری بر کارهای مرتبطی که در این زمینه انجام شده است میپردازیم.
1. مدل کردن رفتار به وسیله دنبالهای از فراخوانیهای سیستمی و الگوهای تکراری
احمدی و همکارانش از کاوش الگوی تکراری برای اولین بار برای شناسایی بدافزارها استفاده کردند. الگوهای تکراری اطلاعاتی را در مورد تکرار توالی خصیصهها به ما میدهد. ایده آنها بر اساس این است که الگوهای تکراری در نمونههای بدافزارها وجود دارد. این الگوها ناشی از زیر روالهای شرطی و بازگشتی موجود در برنامهها است. علاوه بر آن فعالیتهای تکراری در بدافزارها به دلیل استفاده آنها از تکنیکهای رمزگذاری، رمزگشایی و عملیات آلوده سازی وجود دارد. در این مقاله هر کدام از تکنیکهای استخراج شده به عنوان یک خصیصه در نظر گرفته شد. باینریها در قالب یک بردار مدل شدهاند که هر بعد آن نشان دهنده یک خصیصه بود. وجود یا عدم وجود هر کدام از این خصیصهها در هر کدام از باینریها بررسی شده و از الگوریتمهای طبقهبندی برای ساختن مدل استفاده شد. در نهایت آنها موفق شدند با دقت نزدیک به 89% نمونهها را شناسایی نمایند.
چندر اسکار و منوهرن از توالی API ها در زمان اجرا برای شناسایی بدافزارها استفاده کردند. ۴ -گرمها برای مدل کردن توالی فراخوانی API ها استفاده شده است. تعداد زیاد قوانین تولید شده به وسیلهی حذف قوانین زائد و تکراری کاهش یافته و از طبقهبندهای مبتنی بر کاوش ارتباطات برای ساختن مدل بر روی مجموعه خصیصههای استخراج شده استفاده شده است. سیستم ارائه شده دارای سه فاز بر خط، برون خط و آموزش تکرار شونده تشکیل شده است. در فاز برون خط باینریها در محیط کنترل شده اجرا شده و رفتارهای زمان اجرای آنها در قالب فراخوانی API ها استخراج میشود. سپس الگوریتمهای کاوش ارتباطات برای ایجاد قوانین طیقهبندی استفاده میکنند. قوانینی که دارای حمایت و اطمینانی بیش از یک مقدار آستانه باشند، به عنوان قانون های کلی در مجموعه داده باقی میمانند. سپس در فاز بر خط فرخوانیهای سیستمی نمونههای ناشناخته با قوانین موجود مقایسه شده و تصمیم گرفته میشود که نمونه جدید بدافزار یا خوش خیم است. در فاز آموزش تکرار شونده، توالى فراخوانى APl ها و برچسب آنها به مجموعه داده افزوده مىشود. تا مدل بدست آمده به مرور زمان كارا باقى بماند.
2. مدل كردن رفتاربه وسيلهى استفاده از فاصله تشابه
باير و همكارانش بر اساس اين ايده كه تعداد بسيار زيادى از بدافزارها با ايجاد تغييرات در تعداد كمى از فايلهاى بدافزارها ايجاد شدند، سعى در كاهش زمان مورد نياز براى آناليز يوياى بدافزارها مىكنند. امروزه بدافزارهايى ايجاد مىشوند كه مىتوانند كدهاى چند ريختى توليد كرده يا از الگوريتمهاى بستهبندى زمان اجرا استفاده كنند. اين امر باعث مىگردد تا نمونههاى جديد، متفاوت از نمونههاى اوليه باشد اما يك رفتار را نمايش مىدهند. در اين مقاله تكنيكى ارائه شده است كه بر اساس آن از آناليز كامل يك بدافزار چند ريختى در هر بار جلوگيرى مىشود. براى اين منظور نمونههاى جديد براى مدت زمانى كوتاه در محيط كنترل شده مورد تحليل قرار مىگيرند. اگر نمونه جديد به اندازه كافى با نمونههاى از قبل تحليل شده شباهت داشت از ادامه تحليل پوياى نمونه جديد جلوگيرى شده و آناليز آن متوقف مىشود. بر اساس روش بيشنهاد شده، آنها تنها نياز به تحليل كامل 25.25% از نمونهها را داشتند.
ليدر فر و همكارانش سيستمى را براى شناسايى بدافزارها بر اساس محاسبه شباهت بين رفتارهاى زمان اجراى آنها ارائه كردند، در اين سيستم براى كاهش دادن سايز فايلهاى لاگ شده تنها رفتارهايى مرتبط با فعاليتهاى شبكهاى، نوشتن درون فايلهاى سيستمى، رجيسترىها ، آغاز كردن يا پايان دادن به سرويسها و فرايندها ثبت و ضبط مىشوند. فعاليتها به صورت خصيصههاى رشتهاى در قالب يك بردار رفتارى نشان داده شده است، بنابراين دو بدافزار به وسيلهى محاسبه نرخ تعداد فعاليتهايى كه بردارهاى رفتارى آنها به اشتراك گذاشتهاند به تعداد كل عملياتى كه انجام دادهاند با يكديگر مقايسه شده و فاصله شباهت بين آنها محاسبه مى گردد. در بهترين حالت روى مقادير مختلف آستانه دقت 95 درصد روى 1500 نمونه بدست آمد.
در اين روشها انتخاب معيار شباهت و مقدار آستانه بسيار تعيين كننده و حياتى مىباشد. مقدار بالا و يايين آستانه احتمال رخداد منفى كاذب يا مثبت كاذب را افزايش مىدهد. اين ميزان آستانه معمولا وابسته به مجموعه داده بوده و بايستى با گذشت زمان و اضافه شدن نمونههاى جديد مقدار آن به روز رسانى شود. از طرفى تعيين نحوى تعيين مقدار آستانه براى مجموعه دادهها امرى دشوار مىباشد.
3. مدل كردن رفتار به وسيله گراف فراخوانى
جريستودرسكو و همكارانش يك روش مؤثر و كارآمد براى خصوصيات رفتارهاى مخرب ارائه دادند. در اين روش رفتارهاى زمان اجرا نمونهها به وسيله گراف وابستگى بين فراخوانىهاى سيستمى مدل مىشود. فراخوانىهاى سيستمى به عنوان كرههاى گراف در نظر گرفته مىشود و ارتباط بين فراخوانىها يا يال هاى گراف به وسيله آرگومانهاى ورودى و خروجى مدل مىشوند. به اين صورت كه بين دو فراخوانى سيستمى كه آرگومانهاى خروجى يكى متناظر با آرگومانهاى ورودى ديگرى است، يالى كشيده مىشود. گرافهاى مربوط به رفتارهاى بدخيم و نرمال ايجاد شده و زير گراف حاصل كه در فايلهاى خوش خيم وجود ندارند به عنوان رفتارهاى مخرب شناخته مى شوند.
كربلایى و همكارانش از وابستگى بين فراخوانىهاى سيستمى براى نمايش دادن رفتار بدافزارها استفاده كردند. در اين كار تنها از آرگومانهاى ورودى و مقادير بازگشتى براى مشخص كردن ارتباط بين فراخوانىهاى سيستمى استفاده كردند. در صورتى يك يال ميان دو فراخوانى سيستمى رسم مىشود كه مقدار بازگشتى يك فراخوانى سيستمى به عنوان آرگومان ورودى فراخوانى سيستمى ديگر استفاده شود. زير گرافهاى تكرارشونده كه قابليت تمايز بيشترى دارند به وسيلهى الگوريتم gSpam استخراج مىكنند. سپس هر كدام از زير گرافهاى تكرارى حاصل از gSpam به عنوان يك خصيصه در نظر گرفته مىشود و در صورتيكه يك برنامه خوش خيم يا يك بدافزار اين زير گراف را در برداشت، مقدار و در غير اين صورت مقدار صفر به آن نسبت داده مىشود. سپس با استفاده از طبقه بندیهاى مختلف به ارزيابى مدل مىپردازند.
اگر چه گراف يك ساختار مناسب براى مدل كردن رفتار فايلهاى اجرايى است اما كاوش گراف كارى پیچيده و بغرنج بوده و گاهى احتياج به زمانى طولانى دارد. همچنين مقايسه دو گراف زمانى كه گرافها بزرگ باشند سربار بالايى خواهد داشت از طرفى نمونههايى كه از مجموعهى كوچكى از فراخوانىهاى سیستمی استفاده میکنند توسط گرافها نمی توانند مدل شوند.
4. استخراج خصیصهها از فایلهای خوش خیم
در این روش که به آن تشخیص ناهنجاری نیز گفته میشود به این صورت عمل میشود که در ابتدا در فاز آموزش رفتارهای نرمال و قابل قبول سیستم و برنامهها مشخص میشود و سپس در فاز تشخیص هر انحرافی که خارج از این رفتار باشد به عنوان ناهنجاری در نظر گرفته میشود.
هافمر و همکارانش یک روش تشخیص ناهنجاری مبتنی بر دنباله توابع سیستمی را ارائه کرد. دنبالههای کوتاه از توابع سیستمی به عنوان مشخصات نرمال در نظر گرفته میشود. برای مقایسه توابع سیستمی از فاصله همینگ استفاده میشود. فاصلههای همینگ بزرگ، دنبالههای طولانیتر را نشان میدهد که به عنوان ناهنجاری شناخته میشود.
در رویکردی مشابه اسکار و همکارانش به کمک ماشین حالت محدود (FSA) دنباله فراخوانی سیستمی را نشان میدهد. FSAها از روی چندین بار اجرای مختلف برنامهها و ثبت کردن توابع سیستمی بدست میآید. زمانی که یک تابع سیستمی فراخوانی میشود، اگر گذار آن در FSA داده شده نباشد آنگاه به عنوان ناهنجاری در نظر گرفته میشود.
مزیت اصلی این تکنیکها قابلیت شناسایی حملات در نخستین روزهای پیدایش آنها میباشد. از معایب این روش میتوان به نرخ بالای مثبت کاذب و دشواری تشخیص خصیصههایی که در فاز آموزش باید مورد استفاده قرار گیرند، اشاره نمود. چالش اصلی در شناسایی ناهنجاریها تعریف رفتارهای قابل قبولی است که تمامی رفتارهای نرمال را شامل شوند و یک مرز دقیق بین فعالیتهای نرمال و مخرب ایجاد میکند. رفتارهایی که به این مرز نزدیک باشد، به احتمال بیشتر به صورت اشتباه طبقهبندی میشوند.
5. ستخراج خصیصهها علاوه بر فراخوانیهای واسط برنامههای کاربردی
احمد و همکارانش یک دیدگاه پویا برای شناسایی و طبقه بندی بدافزارها به وسیله ترکیب خصیصههای فضایی و مکانی ارائه دادند. خصیصههای فضایی، خصیصههای آماری از قبیل کمترین، بیشترین مقدار، میانگین و واریانس اشارهگرهای API آدرس و سایز پارامترها هستند. خصیصههای مکانی ترتیبهای فراخوانی شده را از طریق مارکف مدل میکند. سیستم ارائه شده تنها فراخوانی API های مربوط به مدیریت حافظه و مقولههای مربوط به ورودی و خروجی فایلها را مانیتور میکند. از طبقهبندیهای معروف مانند SMO j48 I Base و غیره برای بررسی اثر هر دسته از خصیصههای استخراج شده به صورت مجزا و ترکیب آنها استفاده شده است. در بهترین حالت این سیستم قادر است با استفاده از ترکیب خصیصههای فضایی- مکانی، به شناسایی نمونهها با دقت 97 درصد در بین 100 فایل خوش خیم و 416 فایل بدافزار بپردازد.
تییان و همکارانش یک متولوژی پویا برای طبقهبندی بدافزارها بر اساس گزارشهای حاصل از رفتار بدافزارها ارائه دادند. در این روش فایلها در محیط ماشین مجازی برای ۳۰ HookMe ثانیه اجرا میشوند و رفتار آنها به وسیله ابزار پویای ثبت میشود. اطلاعات رشتهای رفتارها به عنوان خصیصه از گزارش ردیابی استخراج میشود. هر فراخوانی API و سایر خصیصههای استخراج شده توسط ابزار به عنوان اطلاعات رشتهای در نظر گرفته میشود. گزارش ردیابی مربوط به هر فایل به یک بردار که شامل این خصیصههای رشتهای است تبدیل میشود. برای تمایز دادن فایلهای خوش خیم و مخرب از طبقهبندیهای مربوط به ابزار وکا از قبیل جنگل تصادفی، SMO، جدول تصمیمگیری و IBI استفاده شده است. در بهترین حالت دقت 97.2 درصد بر روی مجموعهای از 1368 نمونه بدافزار و 456 فایل خوشخیم بدست آمده است.
روشهای تشخیص بدافزار به صورت ایستا
در دهههای اخیر، روشهای جدیدی مبتنی بر امضاء به وجود آمدند، اما یکی از عمدهترین ضعفهای این روشها، ناتوانی آنها در کشف و تشخیص بدافزارهایی بود که نویسندگان آنها از تکنیکهای مبهم سازی در نوشتن آن استفاده میکردند. به همین دلیل پژوهشهای زیادی برای بهبود روشهای مبتنی بر امضاء ارائه شده است.
مانوئل اگلوو همکارانش یک روش اتوماتیک برای حل مشکل فشرده سازی ارائه کردند. هدف اصلی جاستین بازگشایی باینری فشرده شده در یک موتور آنتی ویروس بر اساس امضاهای رایج تشخیص تهدید است. جاستین بر اساس این ایده، بعد از تکمیل روال Unpack یک نسخه از بدافزار اصلی را در فضای حافظه فرایند نگه می دارد. برای به دام انداختن مشکلاتی که در زمان تغییر تنظیمات صفحه توسط باینری رخ میدهد، جاستن تغییرات را ضبط میکند اما تنظیمات خودش را در محلی نگهداری میکند. چالش اصلی روش جاستین، شناخت پایان اجرای روال Unpack است که مانند شروع اجرای کد اصلی برنامه میباشد Unpack که سه متد مختلف برای شناسایی پایان اجرای روال تاکنون معرفی شدهاند.
گیل تاهن و همکارانش، برای تشخیص بدافزارها از امضاء استفاده کردند. اساس این روش تجزیه و تحلیل بخش مشترک بین بدافزارها بود. روش آنها که MaL-ID نام دارد قادر به جدا سازی فایلهای مخرب از فایلهای خوش خیم است. این الگوریتم که بر پایه الگوریتمهای یادگیری ماشین است، ابتدا فایل اجرایی را به فایل دودویی تبدیل کرده و سپس آن را به زیر بخشهایی از بایتها تقسیم میکند و در نهایت هر یک از این زیر بخشها به عنوان یک داده یا یک قطعه کد، دستهبندی میشوند که از این قطعه کدها به عنوان امضای بدافزار استفاده میشد و در تشخیص فایلهای مخرب میتوان از آنها بهره برد. عیب اساسی این روش، ضعف و ناتوانی آن در تشخیص بدافزارهای جدید بود که از تکنیکهای چند شکلی و مبهم سازی استفاده میکردند.
شولتزل و همکاران از تکنیکهای داده کاوی در جهت تشخیص بدافزارهای جدید و ناشناخته استفاده کردند. آنها ابتدا فهرست توابع DLL فراخوانی شده و تعدادی از توابع سیستمی فراخوانی شده در داخل هر DLL را استخراج کردند، سپس از یک الگوریتم که به Ripper معروف است برای یافتن الگوها از داخل اطلاعات DLLها استفاده کردند. بالاترین دقت عملکرد در این روش 83.11 درصد است. نویسنده، روش خود را با روشهای قدیمی بر پایهی امضا مقایسه کرده است و ادعا میکند که روشهای تشخیص مبتنی بر داده کاوی دارای دقتی دو برابر بالاتر از روشهای سادهی تشخیص مبتنی بر امضاء هستند. گرچه این روش خوب است اما هنوز هم دارای دقت بالایی نیست.
رازقی بروجردی و همکاران روشی جدید مبتنی بر خوشهبندی، همترازی دنبالهها و اتوماتاهای غیر قطعی برای تولید خودکار امضاهای رفتاری چندگانه برای تشخیص بدافزارهای چند ریخت پیشنهاد دادند. در روش پیشنهادی، ابتدا برای هر نخ در نمونههای مختلف از هر بدافزار چند ریخت یک دنباله رفتاری استخراج میشود. سپس با اعمال یک الگوریتم خوشهبندی حریصانه دنبالههای رفتاری مشابه در خوشههای یکسان گروهبندی شده و با اعمال یک الگوریتم همترازی دوگانه برای هر خوشه یک الگوی رفتاری ایجاد میشود. در نهایت، با هرس کردن الگوهای رفتاری زاند و تبدیل الگوهای رفتاری باقیمانده به اتوماتاهای غیر قطعی یک امضای رفتاری چندگانه برای بدافزار چند ریخت تولید میشود. نتایچ آزمایشهای انجام شده بر روی یک مجموعه داده از بدافزارهای مختلف نشان میدهد که با استفاده از امضاهای رفتاری چندگانه تولید شده توسط روش پیشنهادی میتوان انواع خانواده بدافزارها را با متوسط دقت 88.8 درصد، متوسط بازخوانی 91.1 درصد و متوسط نرخ مثبت کاذب 0.8 درصد تشخیص داد.
نتیجه گیری
بدون شک بدافزارها یکی از مهم ترین تهدیدهای امنیتی برای فن آوری اطلاعات بوده و هستند. در طی سالیان گذشته، از زمان بدافزارهای ساده تا تهدیدهای پیشرفتهتری همچون ویروسهای پیشرفته امروزی، همواره یکی از مهم ترین دلایل رخدادهای امنیتی این بدافزارها بودهاند. در این مقاله مروری بر انواع روشهای شناسایی بدافزار انجام شده است.
و در آخر:
در این قسمت توضیحاتی آموزنده در مورد بررسی تکنیکهای شناسایی بدافزار گذاشته شد. در آینده مطالب بیشتری را در اختیار شما قرار خواهیم داد، با آرزوی بهترینها برای شما خواننده محترم.
منابع:
مهرنوش بابرى، مهدى محرابى، "بررسی تکنیکهای شناسایی بدافزار".

دیدگاههای بازدیدکنندگان
سلام،مقاله خوبی بود.
435 روز پیش ارسال پاسخسلام و وقتتون بخیر
435 روز پیش ارسال پاسخمتشکرم